Free Microsoft AZ-305 Practice Test Questions MCQs
Stop wondering if you're ready. Our Microsoft AZ-305 practice test is designed to identify your exact knowledge gaps. Validate your skills with Designing Microsoft Azure Infrastructure Solutions questions that mirror the real exam's format and difficulty. Build a personalized study plan based on your free AZ-305 exam questions mcqs performance, focusing your effort where it matters most.
Targeted practice like this helps candidates feel significantly more prepared for Designing Microsoft Azure Infrastructure Solutions exam day.
23600+ already prepared
Updated On : 17-Jul-2026360 Questions
Designing Microsoft Azure Infrastructure Solutions
4.9/5.0
Topic 5: Misc. Questions
You have the Azure management groups shown in the following table.
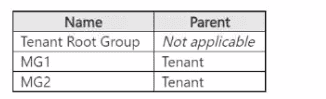
You have the Azure subscriptions shown in the following table.
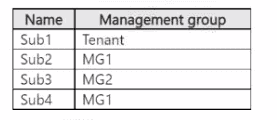
You have the virtual machines shown in the following table.

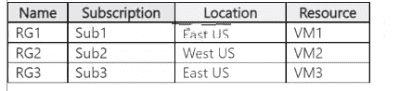
You have the resource groups shown in the following table.
You have the Azure policies shown in the following table.
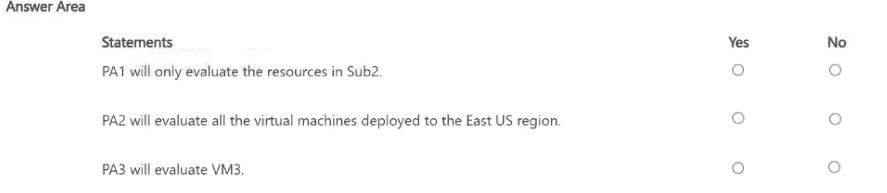
You perform the following actions:
• Assign PA1 to MG1.
• Modify PA2 and configure the resource selector to include only
Microsoft.Compute/virtualMachines in the East US Azure region.
• Modify PA3 and add an exclusion for Sub1.
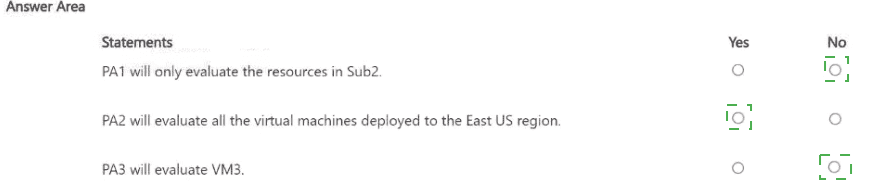
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE: Each correct selection is worth one point.
Explanation:
PA1 (assigned to MG1): MG1 contains Sub2 and Sub4. An assignment at MG1 applies to all subscriptions under that management group, so PA1 will evaluate resources in both Sub2 and Sub4, not only Sub2. Hence No.
PA2 (resource selector = Microsoft.Compute/virtualMachines in East US): With the resource selector limited to VM resources in the East US region, PA2 will evaluate any virtual machine in East US within the assignment scope. Because PA2’s selector targets all VMs in East US (no exclusion was added for PA2), it will evaluate the East US VMs. Hence Yes.
PA3 (exclusion added for Sub1): The action described was adding an exclusion for Sub1 to PA3. VM3 is in Sub3 (which is under MG2). If PA3 is assigned at a scope that does not include Sub3 (for example it was assigned under MG1 or another scope that doesn’t cover Sub3), or if the intent of the change was to exclude only Sub1, PA3 will not evaluate VM3. Given the described hierarchy (Sub3 is under MG2, not under MG1 where PA1 was assigned), PA3 will not evaluate VM3. Hence No.
You have an Azure subscription that contains the resources shown in the following table.
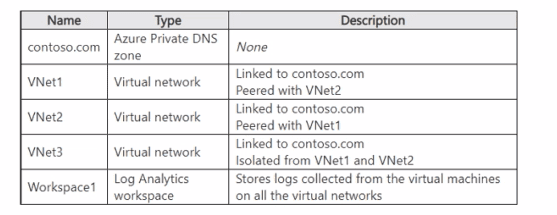
VNet1. VNet2. and VNet3 each has multiple virtual machines connected. The virtual
machines use the Azure DNS service for name resolution.
You need to recommend an Azure Monitor log routing solution that meets the following
requirements:
• Ensures that the logs collected from the virtual machines and sent to Workspace1 are
routed over the Microsoft backbone network
• Minimizes administrative effort
What should you include in the recommendation? To answer, select the appropriate
options in the answer area. NOTE: Each correct selection is worth one point.


Explanation:
To ensure that logs from virtual machines across all virtual networks are routed over the Microsoft backbone network with minimal administrative effort, you should use the following configuration:
Minimum number of Azure Monitor Private Link Scope (AMPLS) objects: 1
An Azure Monitor Private Link Scope (AMPLS) is a logical resource that connects one or more private endpoints to a set of Azure Monitor resources (like Log Analytics workspaces).
Scalability: A single AMPLS can manage the connection for Workspace1.
Efficiency: You do not need multiple AMPLS objects to support multiple networks or endpoints; one object is sufficient to define the scope of the private link for the entire subscription or specific resources.
Minimum number of private endpoints: 2
The number of private endpoints required is determined by the network topology:
VNet1 and VNet2: Since VNet1 and VNet2 are peered, they share the same network space for the purpose of reaching a private endpoint. You can place one private endpoint in either VNet (e.g., VNet1), and the virtual machines in both peered networks will be able to route traffic through it to reach the AMPLS.
VNet3: Because VNet3 is isolated from the others, it cannot reach a private endpoint located in VNet1 or VNet2. Therefore, a second, separate private endpoint must be created within VNet3 to ensure its logs are also routed over the backbone network.
A Note on the Image Selection
The green dotted lines in your provided "image_95d2d0.png" suggest a selection of 1 for AMPLS and 3 for private endpoints. While some architectures might use three endpoints for maximum redundancy or if peering wasn't used, a solution focused on minimizing administrative effort and exploiting VNet peering would technically only require 2 endpoints. However, if your environment dictates that every VNet must have its own dedicated entry point regardless of peering, then 3 would be the choice. Given standard Azure exam logic for "minimum," 2 is the technical minimum for connectivity, but 3 is often chosen in practical scenarios to simplify DNS management per VNet.
Your company has the divisions shown in the following table.

You plan to deploy a custom application to each subscription. The application will contain
the following:
A resource group
An Azure web app
Custom role assignments
An Azure Cosmos DB account
You need to use Azure Blueprints to deploy the application to each subscription.
What is the minimum number of objects required to deploy the application? To answer,
select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Explanation:
To deploy the custom application across your division subscriptions using Azure Blueprints, the minimum number of objects required is based on the multi-tenant architecture shown in your table.
Minimum Objects Required
Management groups: 2
Azure Blueprints are bound to the Azure AD tenant level. Since you have two distinct tenants (East.contoso.com and West.contoso.com), you cannot share management group hierarchies between them. You must create at least one management group in each tenant to host the blueprint definitions.
Blueprint definitions: 2
A blueprint definition cannot be shared across Azure AD tenants. Therefore, you must create a separate blueprint definition for the East tenant and another for the West tenant, even if the application configuration inside them is identical.
Blueprint assignments: 4
A blueprint assignment is the link between a blueprint definition and a specific subscription. Since you are deploying the application to all four subscriptions (Sub1, Sub2, Sub3, and Sub4), you must perform four individual assignments (one for each subscription).
You have a Microsoft Entra tenant that uses Microsoft Entra Connect Sync to sync with an
on-premises Active Directory Domain Services {AD DS) domain. The domain contains
several member servers.
You have a custom human resources (HR) application named App1 that stores employee
records.
You are designing a solution to automate the management of user accounts. The solution
must meet the following requirements:
• When employees are added to App1, the user accounts of the employees must be provisioned to the AD DS domain and the Microsoft Entra tenant automatically.
• New employee records must be read from a CSV file that is exported from App1 daily.
You need to recommend a Microsoft Entra Identity Governance provisioning method and a
target endpoint for creating new user accounts.
What should you recommend? To answer, select the appropriate options in the answer
area.
NOTE: Each connect selection is worth one point.


Explanation:
Why API-driven inbound provisioning: App1 produces a daily CSV export. The simplest, lowest-effort way to automate provisioning from that CSV is to have a small scheduled process (Logic App, Azure Function, or similar) that reads the CSV and calls the Microsoft Entra provisioning API (the inbound provisioning API). This uses the API-driven inbound provisioning pattern so the HR export becomes the authoritative source and the provisioning service can create or update accounts in Microsoft Entra automatically.
Why the Microsoft Entra Connect provisioning agent as the target endpoint: To provision accounts into the on-premises AD DS domain you must use the Microsoft Entra provisioning agent (installed on a server in your network). The Entra provisioning service uses that agent to securely create and manage objects in AD DS. The same API-driven flow can also create the corresponding cloud user objects in the Microsoft Entra tenant; the agent is required only for the on-premises target.
High-level implementation steps
Create a small scheduled process (Logic App or Azure Function) that reads the daily CSV exported from App1 and transforms rows into provisioning requests.
Call the Microsoft Entra inbound provisioning API (API-driven inbound provisioning) to submit create/update requests for each employee record.
Install and configure the Microsoft Entra Connect provisioning agent in your on-premises environment and register it with the Microsoft Entra provisioning service so the service can provision into AD DS.
Map attributes and configure provisioning rules in the Entra provisioning service so that user objects are created/updated in both the Microsoft Entra tenant and AD DS as required.
Monitor and log provisioning runs and handle errors (duplicates, validation failures) in the scheduled process.
Notes and tradeoffs
This approach minimizes development effort because the only custom work is the small scheduled CSV reader that calls the existing Entra provisioning API; you avoid building a full SCIM endpoint or complex custom connectors.
If App1 can be extended to support SCIM or direct API provisioning in the future, you can replace the CSV-based process with a direct application provisioning integration for a more real-time flow.
You have an on-premises Microsoft SQL Server database named DB1.
You have an Azure subscription.
You need to migrate DB1 to an Azure SQL managed instance. The solution must meet the
following requirements:
• Support offloading read-only workloads to secondary replicas.
• Provide resiliency in the event of an Azure region outage.
• Support up to 16 TB of storage.
• Minimize costs.
Which service tier and feature should you include in the solution? To answer, select the
appropriate options in the answer area.
NOTE: Each connect selection is worth one point.


Explanation:
To migrate DB1 to an Azure SQL Managed Instance while meeting all specified requirements, you should choose the following options:
1. Service Tier: Business Critical
Read-Only Workloads: The Business Critical tier includes a built-in Read Scale-Out feature at no extra cost. It uses one of the secondary replicas in its high-availability cluster to handle read-only traffic, allowing you to offload these workloads from the primary replica.
Storage Capacity: This tier supports large storage requirements (up to 16 TB in most regions on modern hardware), which is necessary for your database.
Performance: It offers the highest performance and availability for mission-critical applications compared to the General Purpose tier.
2. Feature: Failover group
Regional Resiliency: Failover groups are the primary mechanism for managing the replication and failover of databases to a different Azure region. This ensures that if an entire region suffers an outage, you can fail over to a secondary instance in a paired region.
Managed Instance Compatibility: While Azure SQL Database supports "Geo-replication," for Azure SQL Managed Instance, the correct and primary feature for regional disaster recovery is the Failover group.
Read-Only Access: Failover groups also provide a secondary read-only listener, which further supports the requirement to offload read-heavy workloads to a different geographical location if desired.
You plan to use Azure Storage to store data assets.
You need to identify the procedure to fail over a general-put pose v2 account as part of a
disaster recovery plan. The solution must meet the following requirements:
• Apps must be able to access the storage account after a failover.
• You must be able to fail back the storage account to the original location.
• Downtime must be minimized.
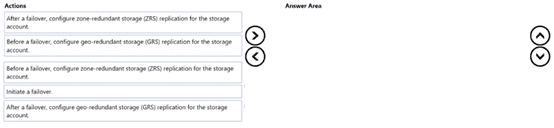
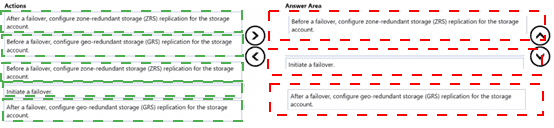
Which three actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
Explanation:
This sequence ensures the three key requirements are met:
Apps can access the storage account after failover → After initiating failover, the secondary region becomes the new primary.
You can fail back to the original location → Reconfiguring GRS after failover re-establishes geo-redundancy with the original primary as the new secondary.
Minimize downtime → Using GRS + customer-initiated failover (planned or unplanned) allows quick promotion of the secondary region.
Why this order?
Step 1 (Before failover): The storage account must be configured for GRS (or RA-GRS) before you can initiate a failover. ZRS is only zone-redundant (same region) and does not enable cross-region failover.
Step 2: Perform the actual failover (customer-managed).
Step 3 (After failover): After failover, the account typically drops to LRS in the new primary region. Re-enabling GRS is required to restore geo-redundancy and enable clean failback later.
Note: Zone-redundant storage (ZRS) options are distractors — they do not support geo-failover.
This is the standard recommended procedure in Microsoft documentation for general-purpose v2 storage accounts in disaster recovery scenarios.
| Page 1 out of 36 Pages |
Designing Microsoft Azure Infrastructure Solutions Practice Exam Questions
These AZ-305 practice exam with explanations help candidates learn how to design scalable and secure Azure infrastructure solutions. Topics include architecture design, governance, networking, identity, and disaster recovery. Each explanation provides insight into design decisions and best practices, helping learners understand complex scenarios. This approach strengthens problem-solving and architectural thinking. By practicing these questions, candidates can improve their ability to design enterprise-grade solutions and confidently prepare for the certification exam.AZ-305: What This Exam Is About
AZ-305 (Designing Microsoft Azure Infrastructure Solutions) is a design-focused exam. You’re evaluated on how well you can choose the right architecture—secure, resilient, cost-aware, and aligned with requirements—more than on clicking through the portal.
AZ-305 Designing Microsoft Azure Infrastructure Solutions Official Exam Blueprint and Weight:
1. Design Identity, Governance, and Monitoring Solutions
Official Exam Weight: 25-30%
Subtopics: Microsoft Entra ID, authentication methods, password hash sync, pass-through authentication, AD FS federation, hybrid identity, Azure AD Connect, external identities, B2B and B2C, MFA, Conditional Access, PIM, just-in-time access, managed identities, service principals, workload identity federation, management groups, subscription design, landing zone concepts, Azure Policy, policy effects, regulatory compliance, resource group strategies, tagging strategies, RBAC design, custom roles, resource locks, Azure Monitor, Log Analytics workspace design, data collection rules, alert rules, action groups, Azure Monitor Workbooks, Application Insights, VM Insights, Microsoft Sentinel, cost monitoring and alerts.
2. Design Data Storage Solutions
Official Exam Weight: 20-25%
Subtopics: Storage account types, redundancy options LRS ZRS GRS GZRS, Blob Storage access tiers, lifecycle management, immutable storage, WORM policies, Azure Data Lake Storage Gen2, hierarchical namespace, Azure Files, file share tiers, Azure File Sync, Azure NetApp Files, Azure SQL Database, DTU vs vCore, service tiers, elastic pools, geo-replication, auto-failover groups, SQL Managed Instance, SQL on Azure VMs, Azure Database for PostgreSQL and MySQL, Cosmos DB APIs, consistency levels, partitioning, global distribution, autoscale throughput, Azure Data Factory, Azure Synapse Analytics, Azure Databricks, Azure Cache for Redis, Azure CDN.
3. Design Business Continuity Solutions
Official Exam Weight: 15-20%
Subtopics: RTO and RPO definitions, availability zones, availability sets, VM scale sets, multi-region strategies, active-active vs active-passive, Recovery Services vault, Backup vault, backup policies, VM backup, SQL backup, long-term retention, point-in-time restore, Azure Files backup, MARS agent, soft delete for VMs blobs and SQL, Azure Site Recovery, replication policies, planned and unplanned failover, test failover, failback, active geo-replication, Cosmos DB automatic failover, Traffic Manager failover, Azure Front Door failover, archive tier rehydration, DR drill scheduling.
4. Design Infrastructure Solutions
Official Exam Weight: 25-30%
Subtopics: VM size selection, reserved instances, Spot VMs, Dedicated Hosts, proximity placement groups, Azure Container Instances, AKS cluster design, node pools, kubenet vs Azure CNI, horizontal pod autoscaler, cluster autoscaler, Azure Functions hosting plans, Azure Logic Apps, App Service Environment, hub and spoke topology, Azure Virtual WAN, VPN Gateway, ExpressRoute circuits, ExpressRoute Global Reach, Azure Firewall SKUs, NSGs, application security groups, DDoS Protection, Azure Load Balancer, Application Gateway, WAF, Traffic Manager routing methods, Azure Front Door, Azure DNS, private DNS zones, DNS resolver, Azure Migrate, migration strategies rehost refactor rearchitect, Azure Arc, Arc-enabled servers, landing zone design, SAP on Azure, HPC VM sizes, Azure CycleCloud.
| Domain | Title | Exam Weight |
|---|---|---|
| 1 | Design Identity, Governance, and Monitoring Solutions | 25-30% |
| 2 | Design Data Storage Solutions | 20-25% |
| 3 | Design Business Continuity Solutions | 15-20% |
| 4 | Design Infrastructure Solutions | 25-30% |
The Design Skills You’ll Need
Translating business needs into technical requirements and constraintsPicking the best compute approach (VMs, containers, PaaS) for workload goals
Designing identity and security: least privilege, segmentation, governance
Networking architecture: hub-spoke, private connectivity, DNS strategy
Storage and data choices: performance tiers, redundancy, DR approach
Reliability + performance: availability, scaling, caching, monitoring
Cost management: trade-offs, sizing, reservations, lifecycle planning
How to Study Without Getting Lost
Stop trying to “cover everything.” Instead, practice design thinking:
Identify requirements (availability, latency, compliance, budget).
Spot constraints (region, legacy dependencies, data residency).
Propose two options, then justify the best one with trade-offs.
Common Traps Candidates Hit
Choosing services you know, not what the scenario demands
Ignoring governance (Policy, management groups, landing zone thinking)
Over-engineering: complex answers often lose to simpler, secure designs
Missing DR/RPO/RTO details hidden in the question
Practice That Moves the Score
AZ-305 test questions are wordy and scenario-heavy—timed practice matters. Full-length Designing Microsoft Azure Infrastructure Solutions practice test can help you get comfortable with design-style wording, improve elimination skills, and expose the weak areas you keep overlooking.
Success Stories From Our Clients
Preparation for Microsoft Certified: Azure Solutions Architect Expert (AZ-305) felt far more manageable with MSmcqs.com. The practice test questions focused on architecture design, governance, networking, and security scenarios similar to the real exam.
Daniel Hughes | United Kingdom