Topic 5: Misc. Questions
Your on-premises network contains an Active Directory Domain Services (AD DS) domain.
The domain contains a server named Server1. Server1 contains an app named App1 that
uses AD DS authentication. Remote users access App1 by using a VPN connection to the
on-premises network.
You have a Microsoft Entra tenant that syncs with the AD DS domain by using Microsoft
Entra Connect.
You need to ensure that the remote users can access App1 without using a VPN. The
solution must meet the following requirements:
• Ensure that the users authenticate by using Azure Multi-Factor Authentication (MFA).
• Minimize administrative effort.
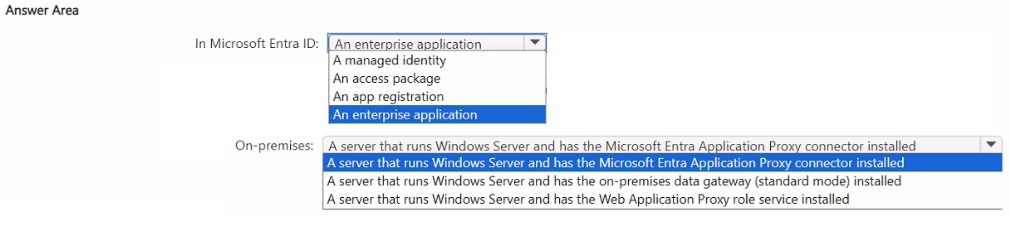
What should you include in the solution? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
Explanation:
This is a classic Microsoft Entra Application Proxy scenario.
Why this combination?
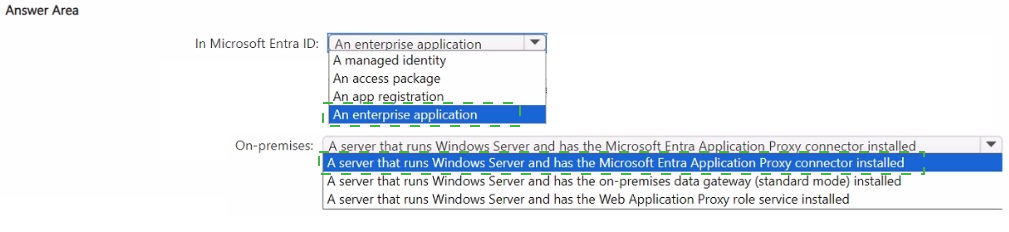
1. Enterprise Application (in Microsoft Entra ID)
You register/publish App1 as an Enterprise Application in the Microsoft Entra admin center.
This enables you to:
Assign users and groups
Configure Single Sign-On (SSO) with Kerberos/NTLM delegation (since App1 uses AD DS authentication)
Apply Conditional Access policies to enforce Azure MFA
This is the correct object type used with Application Proxy.
2. Microsoft Entra Application Proxy Connector (on-premises)
Install the lightweight Application Proxy connector on Server1 (or another Windows server in the domain).
The connector creates an outbound connection to the Microsoft Entra Application Proxy service in the cloud.
External users can then access App1 securely over the internet without a VPN.
No inbound firewall ports need to be opened.
Benefits
Meets both requirements: MFA (via Conditional Access) + no VPN.
Minimizes administrative effort — no need to rewrite the app, move it to Azure, or manage complex networking.
Why the other options are incorrect
Managed Identity / App Registration — Used for application permissions, not for publishing on-premises web apps.
On-premises Data Gateway — Used for Power Platform / Logic Apps connectivity, not for web app publishing.
Web Application Proxy role — This is the older Windows Server role (being replaced by Entra Application Proxy).
This is one of the most common AZ-305 topics related to secure hybrid application access.
You plan to deploy multiple containerized microservice-based apps to Azure Kubernetes
Service (AKS).
You need to recommend a solution that implements the following functions:
• State management
• Pub/sub messaging
• Traffic routing and splitting
The solution must minimize administrative effort.
What should you include in the recommendation for each function? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Explanation:
To recommend a solution for your Azure Kubernetes Service (AKS) microservices deployment that minimizes administrative effort, you should use a combination of Dapr and Istio.
1. State Management: Dapr
Functionality: Dapr (Distributed Application Runtime) provides a dedicated building block for state management. It allows microservices to store and retrieve state from various supported stores (like Redis, Cosmos DB, or Azure SQL) using a simple key/value API.
Administrative Effort: It abstracts the complexity of SDKs and connection management from the application code, allowing developers to switch state stores without changing code.
2. Pub/Sub Messaging: Dapr
Functionality: Dapr also includes a building block for Publish & Subscribe messaging. It enables event-driven architectures where services can communicate asynchronously.
Administrative Effort: Like state management, Dapr provides a uniform API for pub/sub. This means you can use Azure Service Bus, Event Hubs, or Redis as the underlying broker while the application remains decoupled from the specific infrastructure implementation.
3. Traffic Routing and Splitting: Istio
Functionality: Istio is a powerful service mesh designed specifically for managing the network layer of Kubernetes clusters. It excels at traffic routing (directing traffic based on headers, paths, etc.) and traffic splitting (shifting percentages of traffic between different versions of a service for Canary or Blue/Green deployments).
Administrative Effort: In AKS, you can use the Istio-based service mesh add-on, which is a managed offering. This significantly reduces administrative overhead by handling the installation, upgrades, and lifecycle management of the mesh for you.
Understanding the Architecture
Flux (the third option in the menu) is a tool for GitOps and continuous delivery, which is used for synchronizing cluster state with a Git repository, but it does not provide application-level state management or traffic splitting.
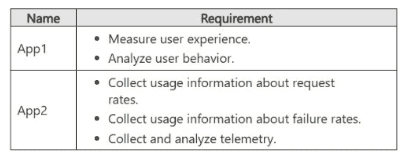
You plan to develop two apps that will be hosted in Azure. The apps must meet the
monitoring requirements shown in the following table.
What should you include in the recommendation for each app? To answer, select the
appropriate options in the answer area.
NOTE Each correct selection is worth one point.

Explanation:
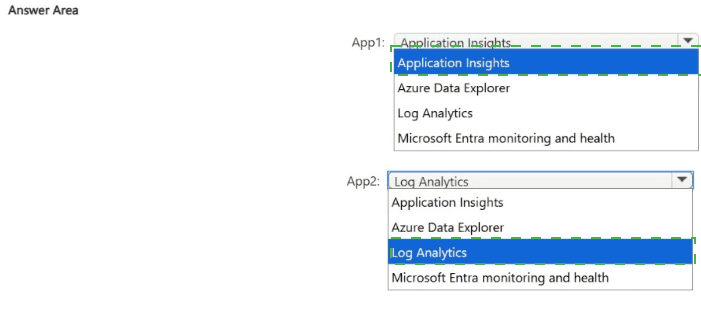
Recommendation: App1 → Application Insights. App2 → Log Analytics. Application Insights is optimized for measuring user experience and analyzing user behavior; Log Analytics (Azure Monitor Logs) is the right store and analysis surface for request/failure rates and general telemetry aggregation.
Recommendation Table
App → Selected service
App1 → Application Insights
App2 → Log Analytics (Azure Monitor Logs)
Why App1 should use Application Insights
Purpose fit: Application Insights is an application performance monitoring (APM) service that collects client and server telemetry (page views, sessions, custom events, traces, dependencies) and provides user experience and behavior analysis features such as funnels, user flows, cohorts, and session metrics.
Low instrumentation effort: SDKs and the Azure Monitor OpenTelemetry distro make it straightforward to instrument web and mobile apps to capture user interactions and performance with minimal code changes.
Built-in UX analytics: Use Application Insights workbooks and usage experiences to analyze feature adoption, drop-offs, and session quality without moving data to another store.
Why App2 should use Log Analytics
Telemetry aggregation and analysis: Azure Monitor Logs (Log Analytics workspace) is designed to collect, retain, and analyze telemetry at scale (requests, failures, custom logs) and supports Kusto Query Language (KQL) for flexible analysis and alerting.
Request and failure metrics: You can ingest application logs, platform diagnostics, and custom metrics into a Log Analytics workspace and run queries to compute request rates, failure rates, SLOs, and create alerts/dashboards.
Centralized operations: Log Analytics is the canonical store for cross-resource telemetry and is ideal when you need long-term retention, complex queries, or to correlate telemetry across multiple apps or services.
Implementation notes and tradeoffs
Integration pattern: Instrument App1 with Application Insights SDK (client + server) to capture UX events; Application Insights stores telemetry in a workspace-backed resource and exposes usage analytics. App2 should send logs/metrics to a Log Analytics workspace (or route Application Insights data to the workspace if you need unified queries).
Correlation: If you need cross-app correlation (traces spanning App1 and App2), configure both to use the same Log Analytics workspace or enable diagnostic settings to route Application Insights data into the workspace.
Costs: Application Insights is optimized for application telemetry and UX analysis; Log Analytics pricing depends on ingestion and retention—use sampling and table plans to control costs.
You have an on-premises datacenter and an Azure subscription. The environment contains
100 databases of various types, including Azure SQL Database, Azure SQL Managed
Instances, Azure Cosmos DB, Microsoft SQL Server, MySQL and Oracle. Multiple apps
access the databases.
You need to recommend a data solution. The solution must meet the following
requirements
• Provide a single searchable catalog of the data in all the databases. The catalog must
contain metadata of the data. The solution must minimize storage requirements.
• Provide a central data lake that contains specific data from multiple databases. The
solution must include a big data engine that can create machine learning models.


Explanation:
For the hybrid environment and data requirements described, the following Azure services should be included in your recommendation:
1. For the searchable data catalog, use: Microsoft Purview Data Map
Single Searchable Catalog: Microsoft Purview is specifically designed to provide a unified data governance solution. Its Data Map automatically captures and indexes metadata from a wide variety of sources, including on-premises SQL Server and Oracle, as well as Azure-native services like Azure SQL and Cosmos DB.
Metadata Focus: It stores only the metadata (schemas, lineage, classifications) rather than the data itself. This directly addresses the requirement to minimize storage requirements, as you aren't duplicating the actual database content.
Discovery: Users can use the Purview Data Catalog to search and discover data assets across the entire 100-database estate using a central interface.
2. For the central data lake, use: Azure Synapse Analytics
Central Data Lake Integration: Azure Synapse Analytics provides a unified workspace that integrates seamlessly with Azure Data Lake Storage Gen2. It can ingest data from multiple databases using built-in pipelines.
Big Data Engine: Synapse includes multiple compute engines, most notably Apache Spark pools. This is the standard "big data engine" for processing massive datasets at scale.
Machine Learning Models: Synapse Spark pools support common ML libraries (Spark MLlib, Scikit-learn, etc.). Furthermore, Synapse has deep native integration with Azure Machine Learning, allowing you to train, register, and deploy models directly from the Synapse environment.
You need to recommend a solution to integrate Azure Cosmos DB and Azure Synapse.
The solution must meet the following requirements:
• Traffic from an Azure Synapse workspace to the Azure Cosmos D8 account must be sent
via the Microsoft backbone network.
• Traffic from the Azure Synapse workspace to the Azure Cosmos DB account must NOT
be routed over the internet.
• Implementation effort must be minimized.
What should you include in the recommendation? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point.
">
Explanation:
To integrate Azure Cosmos DB and Azure Synapse while ensuring all traffic remains on the Microsoft backbone network and never traverses the public internet, you should use the following configuration:
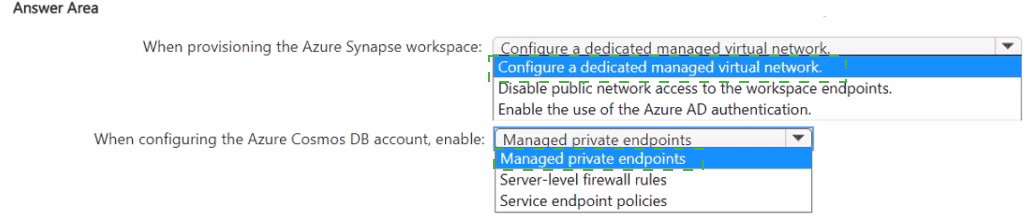
1. When provisioning the Azure Synapse workspace: Configure a dedicated managed virtual network
Network Isolation: By enabling a Managed Virtual Network (VNet), Azure Synapse isolates the compute resources used for integration (like Spark pools or Integration Runtimes) within a network managed by the Synapse service itself.
Backbone Communication: This is a prerequisite for creating private links from Synapse to other Azure services, ensuring that data movement occurs entirely within the Azure network infrastructure rather than over public endpoints.
2. When configuring the Azure Cosmos DB account, enable: Managed private endpoints
Private Link Technology: A Managed Private Endpoint creates a private IP address within the Synapse Managed VNet that maps directly to your Azure Cosmos DB account.
Security & Routing: This ensures that all communication between the Synapse workspace and Cosmos DB is routed over Azure Private Link. Because the endpoint is "Managed" by Synapse, it minimizes implementation effort by handling the network plumbing automatically within Synapse Studio.
Requirement Match: This satisfies the requirement that traffic must NOT be routed over the internet and must stay on the Microsoft backbone network.
Reference
Microsoft Documentation: Managed private endpoints for Azure Synapse
Microsoft Documentation: Azure Synapse Link for Azure Cosmos DB
You have a production line that is monitored by using loT devices.
You are building a project that will process data streams from the loT devices.
You need to recommend a pipeline solution that will perform the following activities:
• Ingest the data streams from the loT devices.
• Analyze the data and identify manufacturing defects among items on the production line.
• When a manufacturing defect is identified, flag the item for removal from the production
line.
What should you include in the recommendation for each activity? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
">
Explanation:
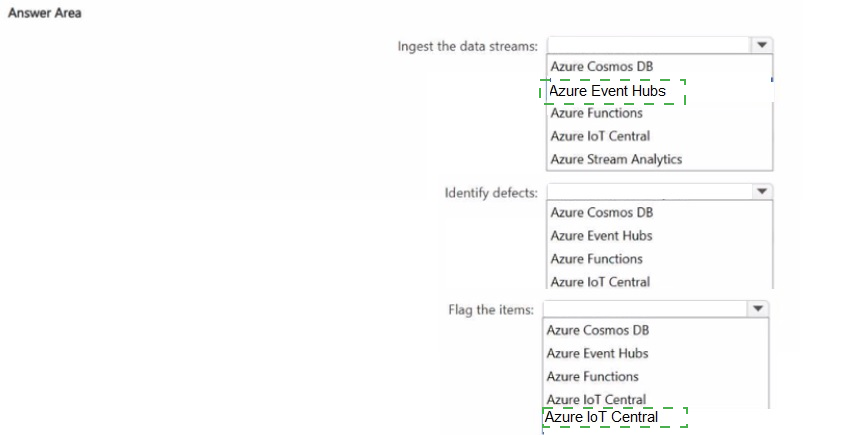
Azure Event Hubs (ingest)
Event Hubs is a high-throughput, fully managed telemetry ingestion service designed to receive millions of events per second from devices and apps. It is the right choice to reliably ingest streaming telemetry from many IoT sensors on a production line with minimal operational overhead.
Azure Stream Analytics (identify defects)
Stream Analytics performs real-time stream processing with built-in windowing and pattern detection. It can run continuous queries (tumbling/sliding windows, anomaly detection functions, or call out to ML models) to analyze telemetry and detect defective items as data arrives. It is a low-admin, cost-efficient choice for real-time detection.
Azure IoT Central (flag items)
IoT Central is a managed IoT application platform that provides device management and command/control capabilities. When Stream Analytics detects a defect, it can output an action (for example via a webhook or Azure Function) that triggers IoT Central to send a command or update device state so the item can be removed from the production line. Using IoT Central minimizes custom device-management code and simplifies issuing removal commands.
Implementation sketch
Devices send telemetry to Event Hubs (or route device telemetry into Event Hubs from your IoT gateway).
Create a Stream Analytics job that reads from Event Hubs, applies windowed aggregations / anomaly detection or calls an ML endpoint, and outputs detection events.
On detection, Stream Analytics outputs to a webhook or Azure Function that calls IoT Central (or directly to IoT Central if supported) to issue the removal command or update device state.
| Page 2 out of 36 Pages |