Topic 5: Misc. Questions
Your on-premises datacenter contains a server named Server1 that runs Microsoft SQL Server 2022. Server1 contains a 30-TB database named DB1 that stores customer data.
Server1 runs a custom application named App1 that verifies the compliance of records in DB1. App1 must run on the same server as DB1.
You have an Azure subscription.
You need to migrate DB1 to Azure. The solution must minimize administrative effort.
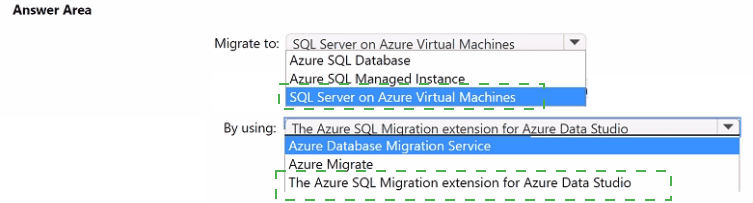
To which service should you migrate DB1, and what should you use to perform the migration? To answer, select the appropriate options in the answer area.
Explanation:
App1 must run on the same server as DB1, requiring full server-level access (not just database-level). Azure SQL Managed Instance and Azure SQL Database do not allow running custom Windows applications on the same compute instance. SQL Server on Azure Virtual Machines provides full OS control, allowing App1 to run on the same VM as DB1. The Azure SQL Migration extension for Azure Data Studio supports offline migration of large databases (30 TB) with minimal effort.
Correct Options:
Migrate to: SQL Server on Azure Virtual Machines
This is the only Azure SQL deployment option that allows you to run custom applications (App1) on the same server as the database. You have full Windows OS and SQL Server instance control. This meets the requirement that App1 must run on the same server as DB1, which is impossible with PaaS offerings.
By using: The Azure SQL Migration extension for Azure Data Studio
This extension supports large database migrations (30 TB) with flexible migration modes (online/offline). It integrates assessment, schema migration, and data movement. For SQL Server on Azure VMs, this extension provides a guided, low-administrative-effort migration experience compared to other tools.
Incorrect Options:
Azure SQL Database - PaaS service with no OS access. Cannot install or run custom applications like App1 on the same server. Eliminates administrative effort but fails the App1 co-location requirement.
Azure SQL Managed Instance - PaaS service with limited instance-level access but still no OS access. Cannot install or run custom Windows applications. App1 cannot run on the same managed instance compute.
Azure Database Migration Service (DMS) - Supports large migrations but requires more configuration and infrastructure setup compared to the Azure SQL Migration extension. Higher administrative effort for a 30-TB database.
Azure Migrate - Designed for server and workload assessment and migration (VMware, Hyper-V, physical). Not the specialized tool for SQL Server database migration to Azure SQL on VMs. Adds unnecessary overhead.
Reference:
Microsoft Learn: SQL Server on Azure Virtual Machines overview; Azure SQL Migration extension for Azure Data Studio; Choose the right SQL Server migration option.
You are building an app named App1 that will monitor thousands of sensors across multiple sites. The app will include the resources shown in the following table.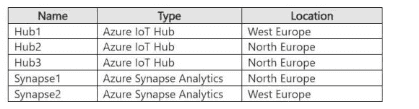
You need to recommend a real lime analytics solution lot App1. The solution must meet the
following requirements;
• Perform analytics on the sensor data in real time.
• Ensure that the solution scales dynamically.
• Minimize development effort
• Minimize costs.
What is the minimum number of Azure Stream Analytics jobs you should deploy?
A. 1
B. 2
C. 3
D. 6
You plan to deploy an Azure App Service web app named App1 that will service users in a single geographical region. App1 will access a highly available database named DB1 that will be hosted on two Azure virtual machines named VM1 and VM2.
You need to recommend a solution that meets the following requirements:
• Uses Azure Web Application Firewall (WAF) to minimize the risk of a web-based attack against App1
• Ensures that administrators can access VM1 and VM2 securely from the internet
• Ensures that traffic from App1 to DB1 is NOT sent via the internet
• Minimizes costs
What should you include in the recommendation for each requirement? To answer, select the appropriate options in the answer area.

You have an on-premises network.
You have an Azure subscription.
You plan to centralize the collection and analytics of Azure and on-premises resources by using Log Analytics.
You are evaluating the cost implications of using the Basic log data plan versus the Analytics log data plan.
What will increase costs by using the Basic log data plan, and what will reduce costs by using the Basic log data plan? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Explanation:
The Basic log data plan has lower ingestion costs but lacks full query capabilities and alerting support compared to the Analytics log data plan. Basic logs are cheaper to ingest but cannot be used for log-based alerts or high-performance log queries. Using Basic logs reduces ingestion costs, but increases costs for alerts (because you may need alternative solutions) and reduces query capabilities.
Correct Options:
Increase costs: Alerts
Basic log data plan does not support direct log-based alerts. To achieve alerting on Basic logs, you may need to export data to external systems or use additional services (e.g., Azure Monitor metrics, Event Hubs, or third-party tools), which increases overall cost or complexity. Analytics logs include native alerting at no extra per-alert cost beyond ingestion.
Reduce costs: Ingestion
The Basic log data plan has significantly lower ingestion costs per gigabyte compared to the Analytics log data plan. For high-volume, verbose logs that do not require real-time query or alerting, Basic logs reduce overall spending on data ingestion while still storing the data for basic retrieval.
Incorrect Options:
Ingestion (for increase costs) - This is incorrect because Basic logs actually reduce ingestion costs, not increase them. Ingestion cost is the primary saving of the Basic plan.
Log queries (for reduce costs) - Basic logs do not support rich log queries with full KQL capabilities. Query performance and features are reduced, but this is a functional limitation, not a cost reduction. Basic queries are not cheaper; they are simply less capable.
Reference:
Microsoft Learn: Azure Monitor Logs pricing; Basic Logs versus Analytics Logs; Alerting support for Basic Logs.
| Page 6 out of 36 Pages |