Free Microsoft AB-731 Practice Test Questions MCQs
Stop wondering if you're ready. Our Microsoft AB-731 practice test is designed to identify your exact knowledge gaps. Validate your skills with AI Transformation Leader questions that mirror the real exam's format and difficulty. Build a personalized study plan based on your free AB-731 exam questions mcqs performance, focusing your effort where it matters most.
Targeted practice like this helps candidates feel significantly more prepared for AI Transformation Leader exam day.
2770+ already prepared
Updated On : 17-Jul-202677 Questions
AI Transformation Leader
4.9/5.0
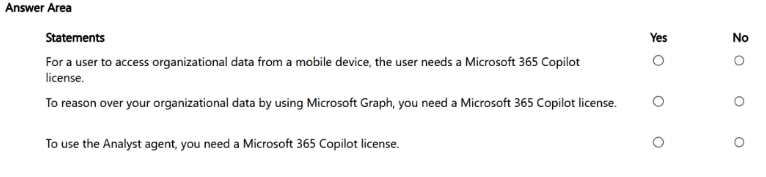
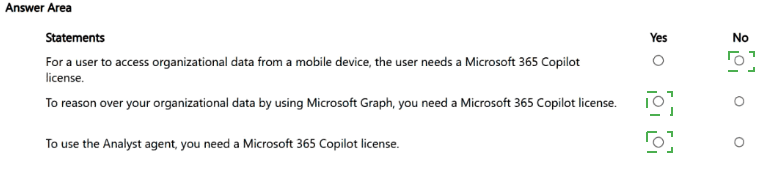
For each of the following statements, select Yes if the statement is true. Otherwise, select
No. NOTE: Each correct selection is worth one point
Explanation:
Why the Selected Options Are Correct
Statement 1 is False (No): Regression is used to predict continuous, quantitative numeric values (e.g., forecasting a house price or tomorrow's temperature). Predicting a categorical label or discrete class is the definition of Classification.
Statement 2 is False (No):Classification sorts data data points into distinct buckets, categories, or labels (e.g., determining whether an email is "Spam" or "Not Spam"). Predicting continuous numeric trends is the role of Regression.
Statement 3 is True (Yes): Clustering operates entirely without pre-labeled historical outcomes (unsupervised learning). It functions by examining the mathematical distance between data feature vectors to organically group similar records together into distinct clusters (e.g., segmenting customer demographics based on purchasing behavior).
Why the Alternate Selections Are Incorrect
Swapping the definitions of Regression and Classification is a classic trap; their definitions in Statements 1 and 2 are exactly reversed.
Marking No on Statement 3 misrepresents the fundamental definition of clustering algorithms (such as K-Means or Hierarchical clustering), which are explicitly designed for unsupervised groupings.
References
Microsoft Learn: Understand machine learning types – Differentiates supervised learning (Classification for discrete labels, Regression for continuous numbers) from unsupervised learning (Clustering for unlabelled pattern grouping).
Azure AI Fundamentals Training Manual: Explains the foundational mathematical differences between target output metrics for standard machine learning workloads.
For each of the following statements, select Yes if the statement is true. Otherwise, select
No. NOTE: Each correct selection is worth one point.


Explanation
Why the Selected Options Are Correct
Statement 1:This is the foundational definition of Machine Learning (ML). Unlike traditional software engineering where a developer writes explicit, hard-coded rules (e.g., if/else blocks), ML algorithms use statistical techniques to scan training datasets, discover hidden mathematical patterns, and build an internal model to reason over new data dynamically.
Statement 2: Deep Learning (DL) is a specialized branch under the machine learning umbrella. It specifically relies on Artificial Neural Networks (ANNs) containing an input layer, an output layer, and multiple hidden layers (hence "deep") to automatically extract high-level features from complex, unstructured data.
Statement 3: Generative AI is a specific subset of broader Artificial Intelligence. While classical AI focuses on analyzing, classifying, or predicting based on existing data points, generative architectures (such as GANs, Transformers, and Diffusion models) learn the underlying distribution of a dataset to create entirely new, realistic content from scratch.
Why the Alternate Selections Are Incorrect
Choosing No on any of these parameters fundamentally misrepresents the established hierarchy of artificial intelligence domains.
Machine learning cannot exist with manual hard-coding; deep learning is structurally defined by its multi-layered networks; and generative AI's distinguishing baseline characteristic is content creation rather than basic data classification.
References
Microsoft Learn: Introduction to Azure Machine Learning – Graphically maps the structural nesting of technology branches where Deep Learning sits inside Machine Learning, which sits inside the broader landscape of Artificial Intelligence.
Azure AI Fundamentals (AI-900 Core Curriculum): Fundamental AI Concepts – Validates the explicit classification of Generative AI as an AI capability optimized for synthesizing unique, human-like contextual outputs.
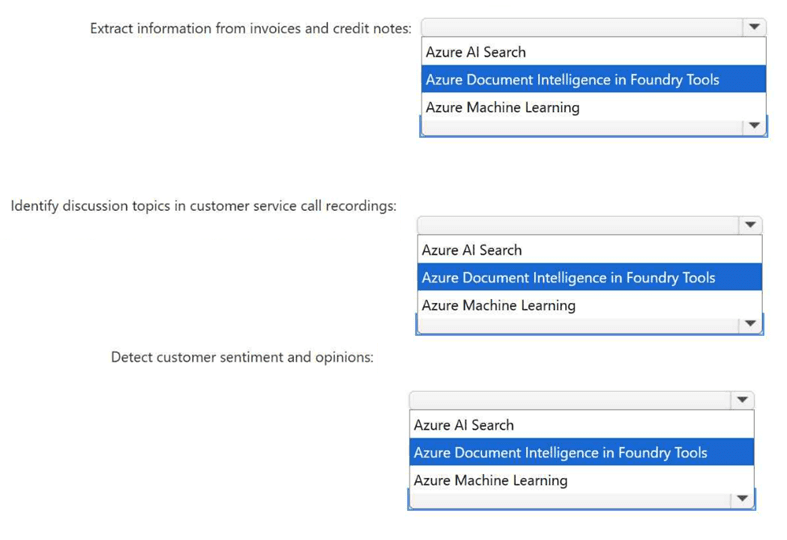
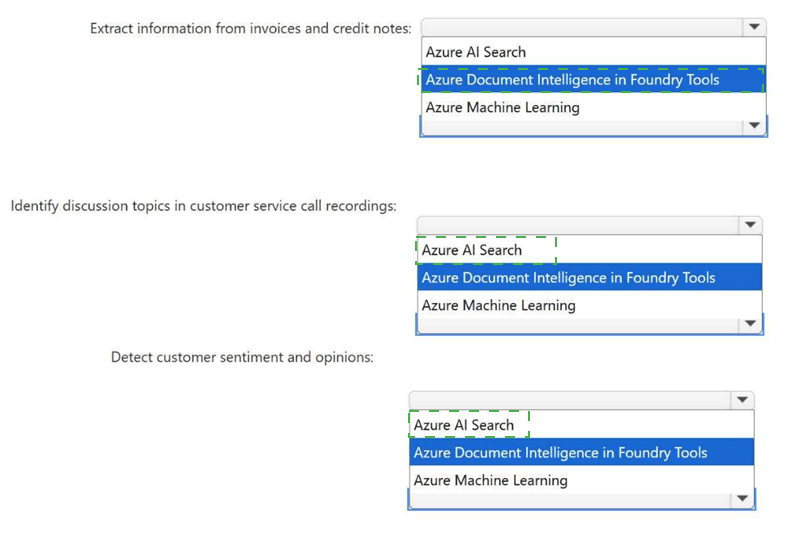
You need to recommend an AI solution for each task. The solutions must use prebuilt AI
capabilities to reduce development time. What should you recommend for each task?
Explanation:
Why the Selected Options Are Correct
Extract fields from invoices $\rightarrow$ Document intelligence: Invoices are structured or semi-structured documents containing specific data points (e.g., invoice ID, line items, total tax). Azure AI Document Intelligence provides prebuilt models explicitly trained to recognize and extract these standard transactional key-value pairs without needing manual training.
Identify defective products $\rightarrow$ Custom vision: General computer vision can recognize standard objects (like a bottle or a tire), but identifying a defect (like a crack or a missing cap) requires training a model on company-specific product images. Azure AI Custom Vision provides a prebuilt framework where you quickly upload normal vs. defective images to build a specialized classifier with minimal code.
Transcribe audio recordings $\rightarrow$ Speech-to-text: Converting spoken audio files directly into structured text strings is the fundamental out-of-the-box purpose of the prebuilt Azure AI Speech service's Speech-to-Text API.
Why the Other Options Are Incorrect
Computer vision is designed for general image tagging, facial detection, and optical character recognition (OCR), but it lacks the specialized structural logic needed to automatically map document fields like invoice data or target specific assembly line manufacturing anomalies.
Language understanding parses text to determine user intent and extract entities (used heavily in chatbots); it cannot ingest raw audio files directly or process visual product images.
References
Microsoft Learn: What is Azure AI Document Intelligence? – Details the prebuilt invoice recipe used to automatically parse vendor document properties.
Microsoft Azure Architecture Guide: Cognitive Services Choice Matrix – Confirms that Speech-to-Text handles raw voice transcription workloads, while Custom Vision handles unique object classification tasks.
| Page 1 out of 8 Pages |