Topic 6: Misc. Questions
You have an Azure SQL database named DB1 that contains a table named Table 1.
You run a query to load data into Table1.
The performance metrics of Table1 during the load operation are shown in the following
exhibit.
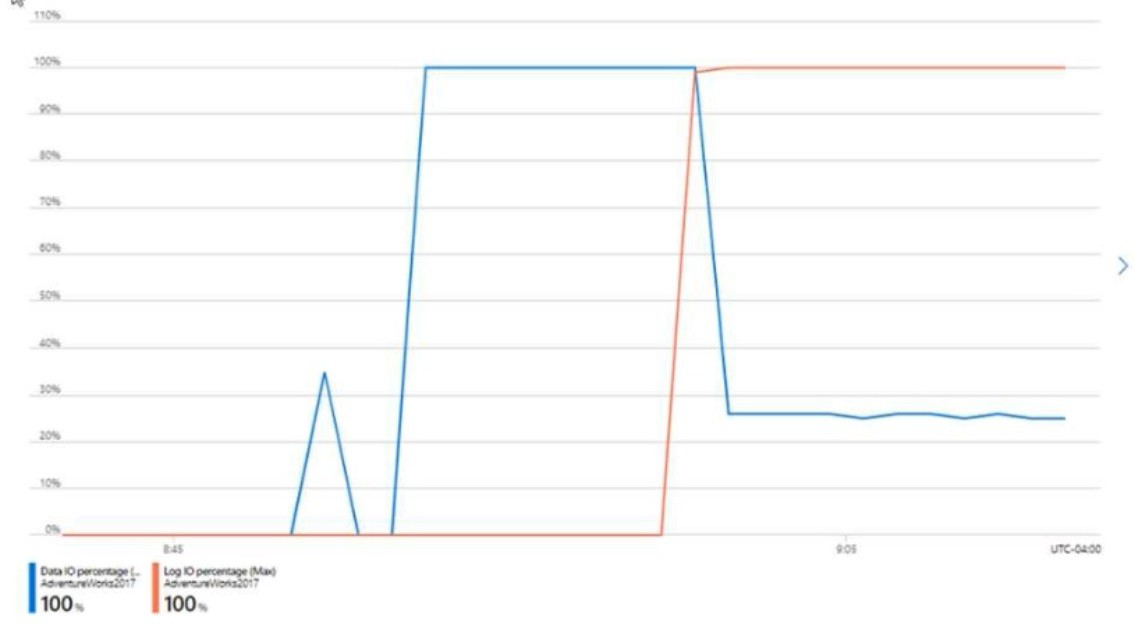
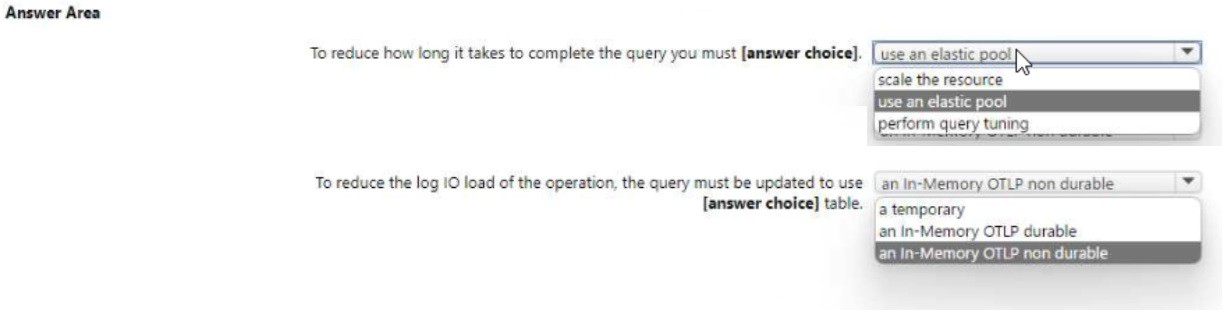
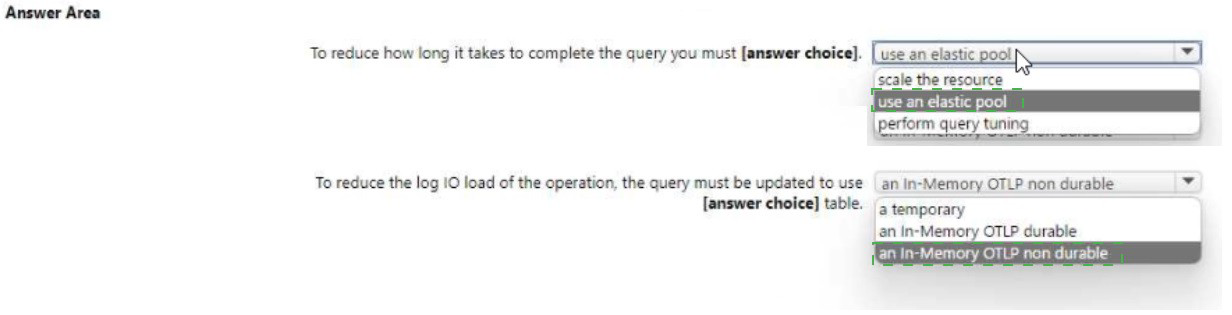
Use the drop-down menus to select the answer choice that completes each statement
based on the information presented in the graphic. NOTE: Each correct selection is worth
one point.
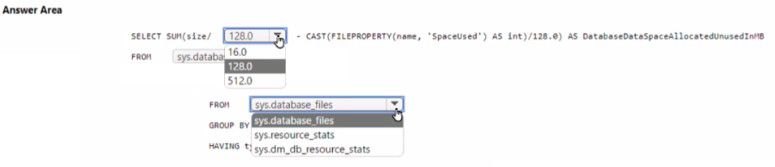
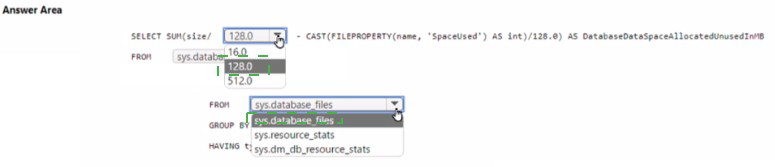
You have an Azure SQL database named D61.
You need to identify how much unused space in megabytes was allocated to DB1.
How should you complete the Transact-SQL query? To answer select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.
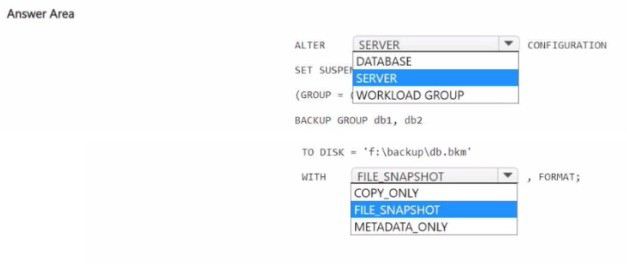
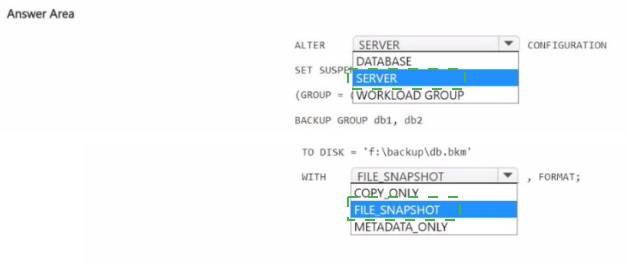
You have a SQL Server on Azure Virtual Machines instance named SQLVM1 that contains
two databases named DB1 and DB2. The database and log files for DB1 and DB2 are
hosted on managed disks.
You need to perform a snapshot backup of DB1 and DB2
How should you complete the I SQL statements? To answer, select the appropriate options
in the answer area.
NOTE: Each correct selection is worth one point.
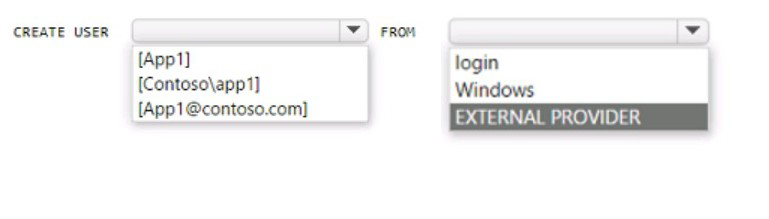
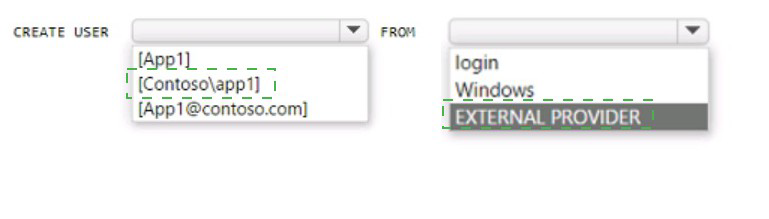
You have an Azure subscription that is linked to an Azure AD tenant named contoso.com.
The subscription contains an Azure SQL database named SQL 1 and an Azure web
named app1. App1 has the managed identity feature enabled.
You need to create a new database user for app1.
How should you complete the Transact-SQL statement? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure SQL managed instance named Server1 and an Azure Blob Storage
account named storage1 that contains Microsoft SQL Server database backup files.
You plan to use Log Replay Service to migrate the backup files from storage1 to Server1.
The solution must use the highest level of security when connecting to storage1.


| Page 9 out of 34 Pages |