Topic 6: Misc. Questions
You Save an Azure SCX database named DB1.
You need to query the fragmentation information of data and indexes for the tables in D61.
Which command should you run?
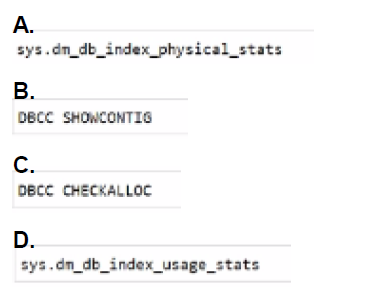
A. Option A
B. Option B
C. Option C
D. Option D
You plan to deploy an Always On failover cluster instance (FCI) on Azure virtual machines.
You need to provision an Azure Storage account to host a cloud witness for the
deployment.
How should you configure the storage account? To answer, select the appropriate options
in the answer area.
NOTE: Each correct selection is worth one point.


You have an Azure SQL database named that contains a table named Table1.
You run a query to bad data into Table1.
The performance Of Table1 during the load operation are shown in exhibit.
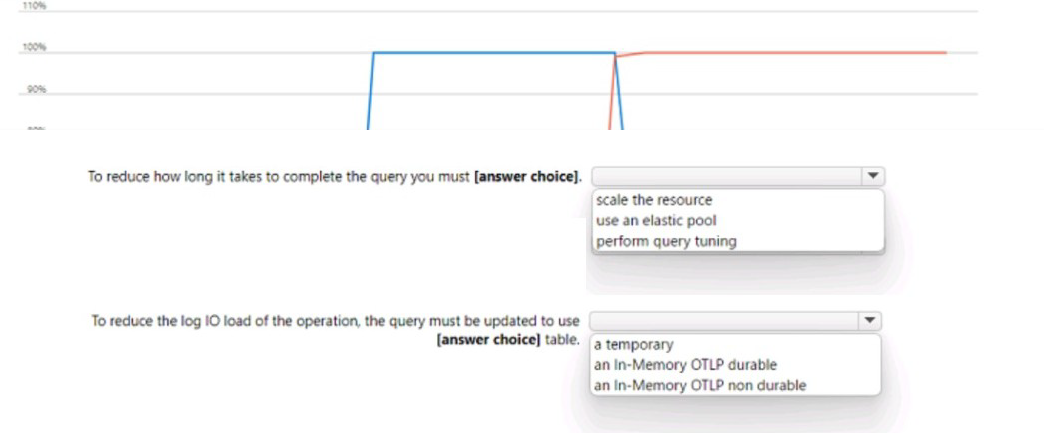
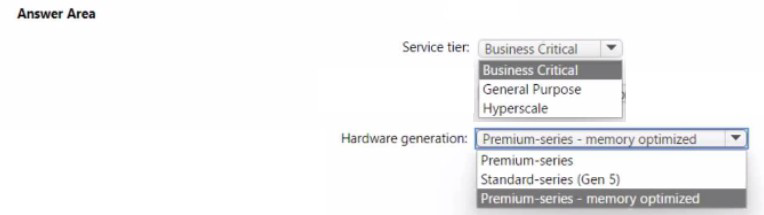
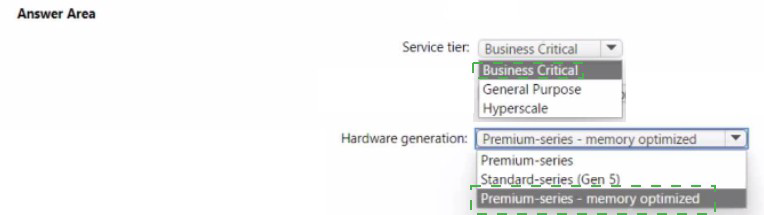
You have an Azure subscription.
You need to deploy an Azure SQL managed instance that meets the following
requirements:
• Optimize latency.
• Maximize the memory-to-vCore ratio.
Which service tier and hardware generation should you use? To answer, select the
apocopate options in the answer area.
NOTE: Each correct selection is worth one point.
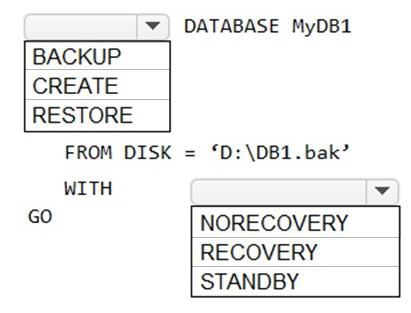
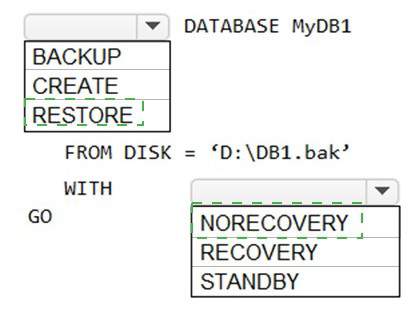
You have two Azure virtual machines named VM1 and VM2 that run Windows Server 2019.
VM1 and VM2 each host a default Microsoft SQL Server 2019 instance. VM1 contains a
database named DB1 that is backed up to a file named D:\DB1.bak.
You plan to deploy an Always On availability group that will have the following
configurations:
VM1 will host the primary replica of DB1.
VM2 will host a secondary replica of DB1.
You need to prepare the secondary database on VM2 for the availability group.
How should you complete the Transact-SQL statement? To answer, select the appropriate
options in the answer area.
You have a SQL Server on Azure Virtual Machines instance that hosts a 10-TB SQL
database named DB1.
You need to identify and repair any physical or logical corruption in DB1. The solution must
meet the following requirements:
• Minimize how long it takes to complete the procedure.
• Minimize data loss.
How should you complete the command? To answer, select the appropriate options in the
answer area NOTE: Each correct selection is worth one point.


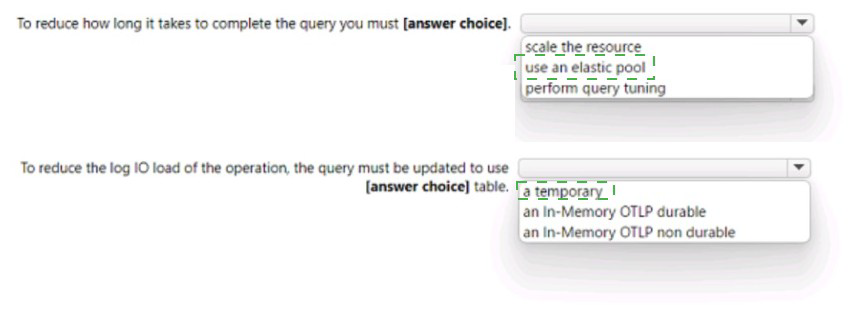
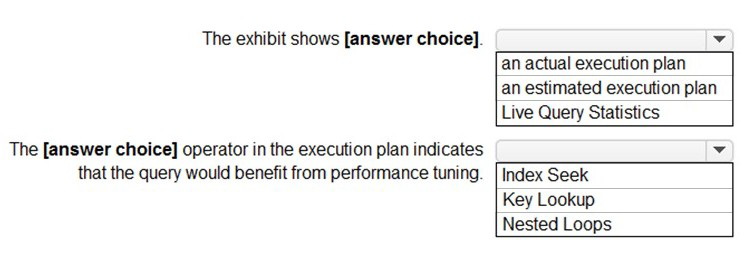
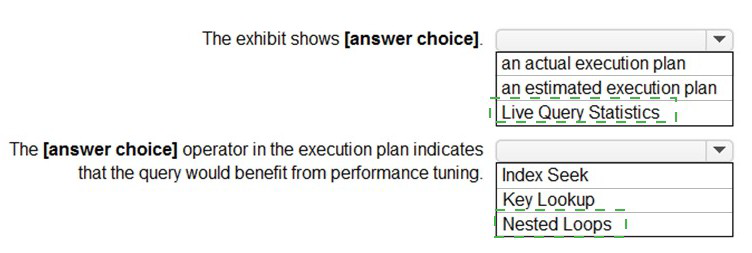
You have an Azure SQL database.
You are reviewing a slow performing query as shown in the following exhibit.
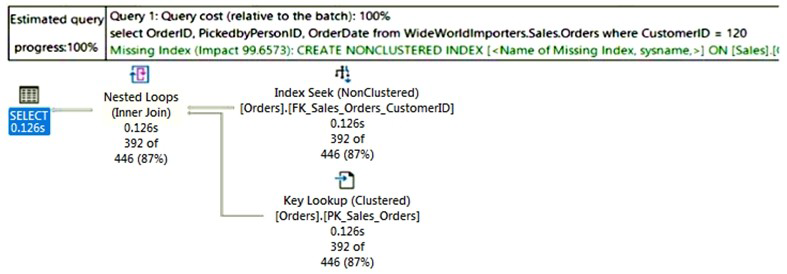
Use the drop-down menus to select the answer choice that completes each statement
based on the information presented in the graphic.
| Page 11 out of 34 Pages |