Topic 3: Misc. Questions
You are planning the DHCP1 migration to support the DHCP migration plan.
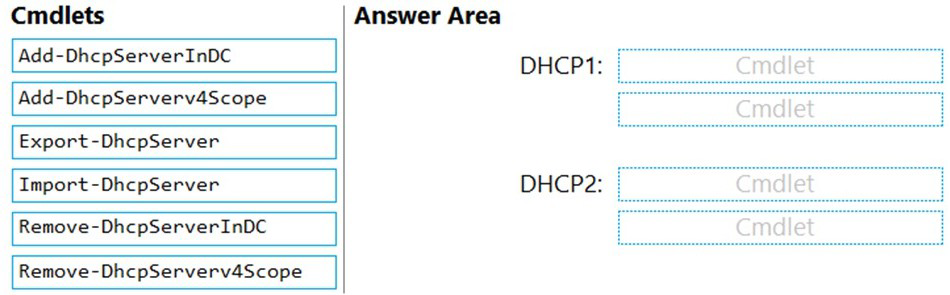
Which two PowerShell cmdlets should you run on DHCP1, and which two PowerShell
cmdlets should you run on DHCP2? To answer, drag the appropriate cmdlets to the correct
servers. Each cmdlet may be used once, more than once, or not at all. You may need to
drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
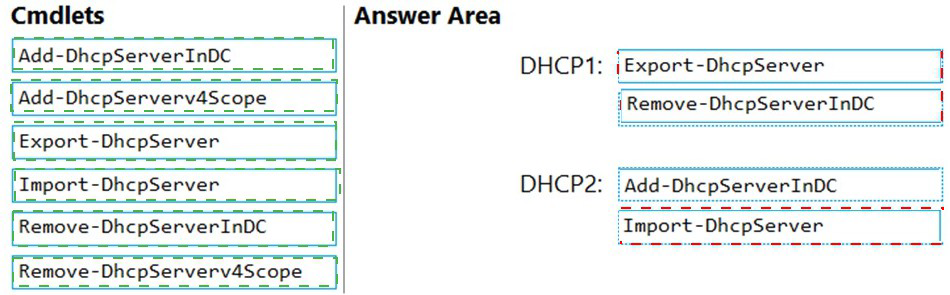
When migrating DHCP servers, you need to export the configuration from the source server and import it on the destination server. The Export-DhcpServer cmdlet exports DHCP scope configurations, options, and leases from the source server. The Import-DhcpServer cmdlet imports this data to the destination server.
Correct Option:
DHCP1 (Source Server):
Export-DhcpServer: This cmdlet exports the DHCP server configuration, including all scopes, options, and lease information, to a specified file. This captures all settings from DHCP1 for migration to the new server.
DHCP2 (Destination Server):
Import-DhcpServer: This cmdlet imports the DHCP configuration from the exported file into the DHCP2 server. It recreates all scopes and settings on the new server.
Add-DhcpServerInDC: After importing the configuration, this cmdlet authorizes the new DHCP server (DHCP2) in Active Directory, allowing it to start leasing IP addresses in the domain.
Incorrect Option:
Add-DhcpServerv4Scope: Used for creating individual scopes manually, not for bulk migration.
Remove-DhcpServerInDC: Used for deauthorizing a DHCP server, not for migration.
Remove-DhcpServerv4Scope: Used for deleting scopes, not for migration.
Reference:
Microsoft Learn: Export-DhcpServer cmdlet
Microsoft Documentation: Migrate DHCP to Windows Server
Your network contains an Active Directory Domain Services (AD DS) domain that has the
Active Directory Recycle Bin enabled. All domain controllers are backed up daily.
You accidentally remove all the users from a domain group.
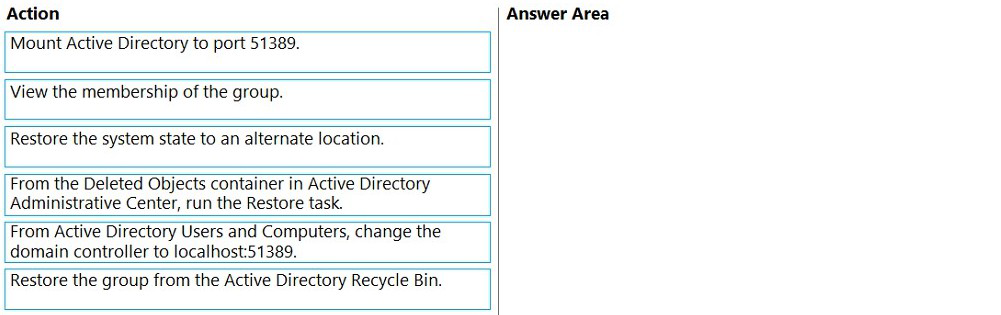
You need to get a list of the users that were previously in the group.
Which four actions should you perform in sequence from a domain controller? To answer,
move the appropriate actions from the list of actions to the answer area and arrange them
in the correct order.
Explanation:
Since the Active Directory Recycle Bin is enabled, you can restore the deleted group members without a full system state restore. However, you cannot directly view historical group membership. The solution involves mounting an authoritative AD snapshot to view the group's previous state, then restoring the group from Recycle Bin.
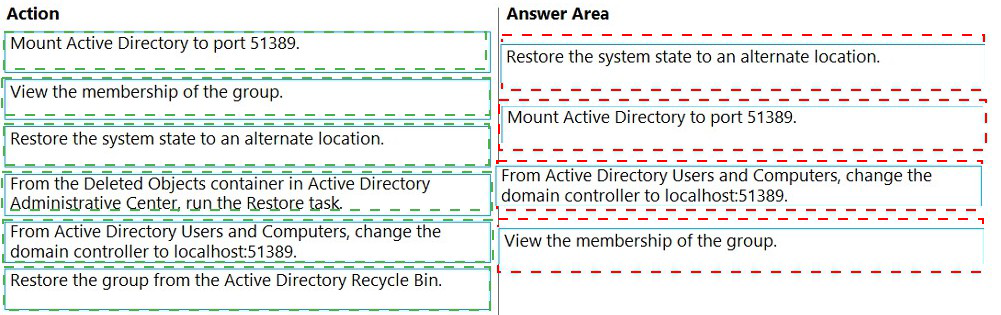
Correct Order:
Restore the system state to an alternate location: You must first restore a backup snapshot of AD to an alternate directory to access historical data without affecting the live domain.
Mount Active Directory to port 51389: Using the ntdsutil command, mount the restored snapshot database and expose it on a specified LDAP port (51389) for querying.
From Active Directory Users and Computers, change the domain controller to localhost:51389: Open ADUC and target the mounted snapshot instance to view AD as it existed at the backup time.
View the membership of the group: With ADUC connected to the snapshot, you can now browse the group and see the complete list of users who were members before the accidental removal.
Incorrect Option:
From the Deleted Objects container, run the Restore task: This restores the group but does not help view the historical membership list first.
Restore the group from AD Recycle Bin: This would restore the group but not the membership list, and membership information is not stored in Recycle Bin.
Performing Recycle Bin restore before viewing membership: You need to identify which users were in the group before deciding whether to restore it.
Reference:
Microsoft Learn: Active Directory Recycle Bin step-by-step
Microsoft Documentation: Ntdsutil directory service management
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result,
these questions will not appear in the review screen.
You have a failover cluster named Cluster! that hosts an application named Appl.
The General tab in App1 Properties is shown in the General exhibit (Click the General tab.)
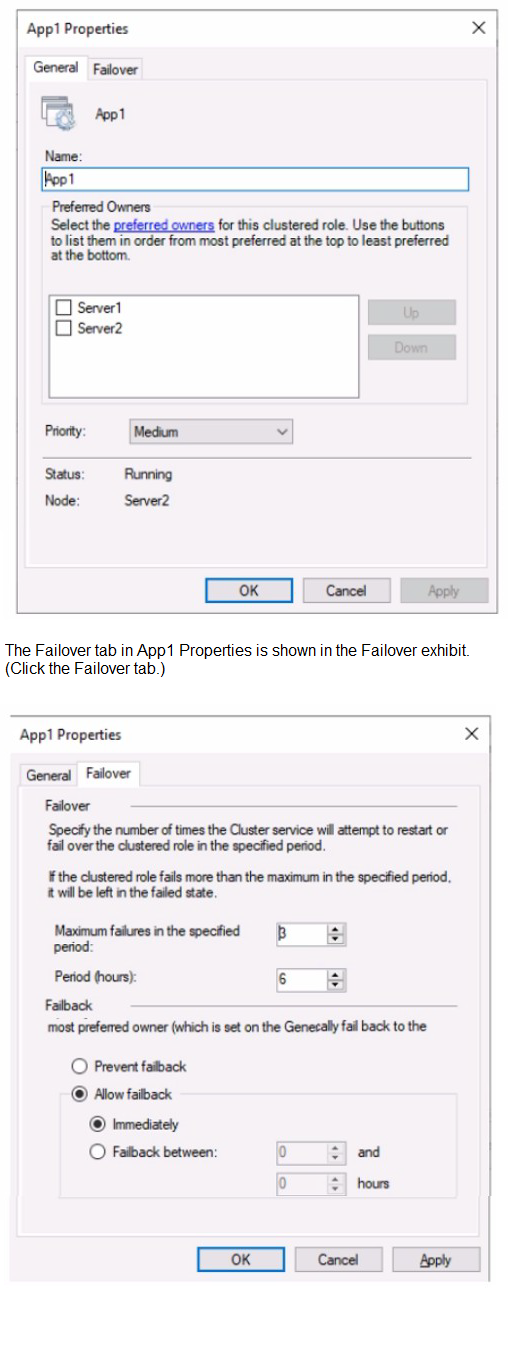
Server2 shuts down unexpectedly.
You need to ensure that when you start Server2, App1 continues to run on Server2.
Solution: You pause the Server1 node in Cluster1 and then start Server1.
Does this meet the goal?
A. Yes
B. No
Explanation:
When Server2 shuts down unexpectedly, App1 will fail over to Server1 (the other available node). The goal is to ensure that when Server2 starts again, App1 continues to run on Server2 (moves back). Pausing Server1 prevents it from hosting applications but does not automatically trigger failback. Without configuring failback settings in App1 properties, the application will remain on Server1 after it is resumed.
Correct Option:
B. No:
Pausing Server1 and then starting Server1 does not automatically move App1 back to Server2. Even if Server1 is paused, App1 would fail over to Server1 when Server2 shuts down. When Server2 restarts, App1 would still run on Server1 unless failback is explicitly configured in the application properties to allow automatic failback to the preferred owner (Server2).
Incorrect Option:
A. Yes:
This would be incorrect because pausing a node only prevents new resources from coming online on that node. It does not trigger failback of existing resources. The solution fails to meet the goal as App1 would continue running on Server1 after Server2 starts, not on Server2 as required.
Reference:
Microsoft Learn: Configure failover and failback settings for cluster roles
Microsoft Documentation: Cluster failover and failback behavior
You manage 200 physical servers that run Windows Server.
You plan to migrate the servers to Azure.
You need to prepare for discovery of the servers by using Azure Migrate.
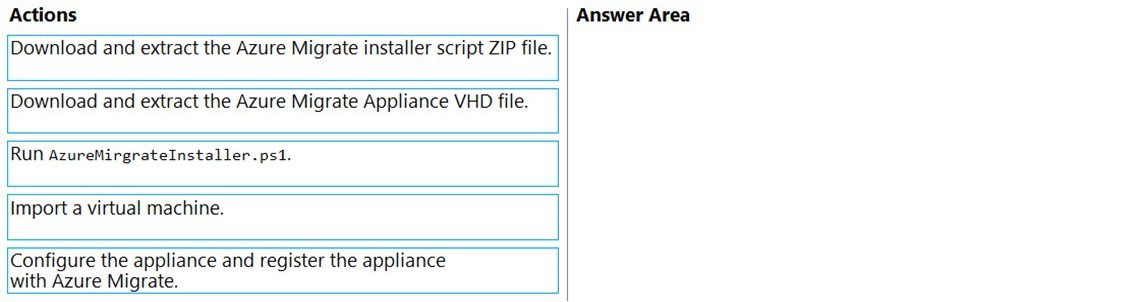
Which three actions should you perform in sequence on a physical server? To answer,
move the appropriate actions from the list of actions to the answer area and arrange them
in the correct order.

Explanation:
To discover physical servers using Azure Migrate, you need to deploy the Azure Migrate appliance on a physical server. The appliance is deployed using a PowerShell script that configures the server as the appliance. After script execution, you configure and register the appliance with your Azure Migrate project to begin discovery.
Correct Order:
Download and extract the Azure Migrate installer script ZIP file:
The first step is to download the installer script package from the Azure portal and extract its contents to the physical server that will host the appliance.
Run AzureMigrateInstaller.ps1:
Execute the PowerShell script to install and configure the Azure Migrate appliance components on the physical server. This script deploys the necessary services and configurations.
Configure the appliance and register the appliance with Azure Migrate:
After installation, access the appliance configuration manager, complete the prerequisites check, and register the appliance with your Azure Migrate project to start server discovery.
Incorrect Option:
Download and extract the Azure Migrate Appliance VHD file:
This method is for deploying the appliance as a VMware VM, not for physical servers. Physical servers require the PowerShell script deployment method.
Import a virtual machine:
This action is not part of the physical server discovery process. The appliance is configured directly on the physical server, not imported as a VM.
Reference:
Microsoft Learn: Prepare for physical server discovery and assessment
Microsoft Documentation: Deploy Azure Migrate appliance on a physical server
Your network contains an Active Directory Domain Services (AD DS) domain.
You need to implement a solution that meets the following requirements:
Ensures that the members of the Domain Admins group are allowed to sign in only
to domain controllers
Ensures that the lifetime of Kerberos Ticket Granting Ticket (TGT) for the
members of the Domain Admins group is limited to one hour
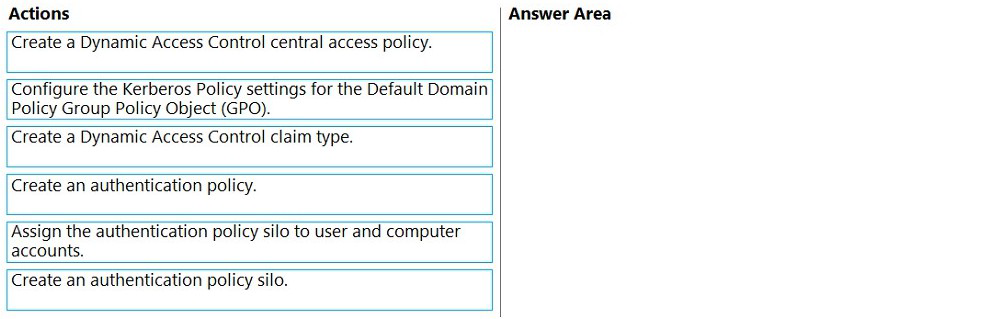
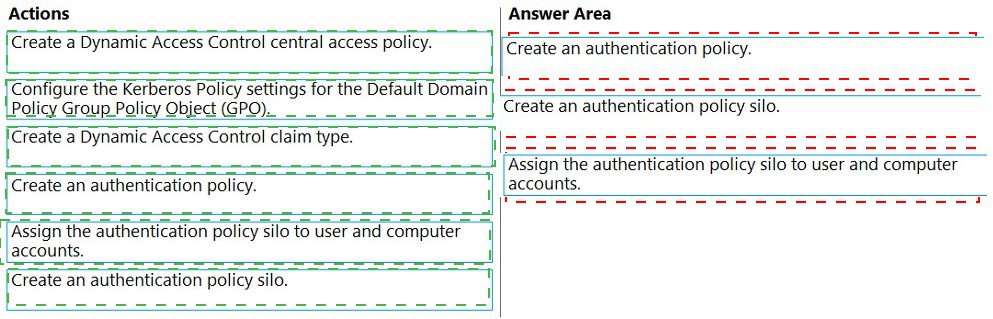
Which three actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
Explanation:
To restrict Domain Admins sign-in to domain controllers and limit their Kerberos TGT lifetime, you need to use Authentication Policies and Authentication Policy Silos, features available with domain functional level 2012 R2 or higher. These provide fine-grained control over Kerberos ticket properties and sign-in restrictions for high-privilege accounts.
Correct Order:
Create an authentication policy silo: First, create a container (silo) that will group accounts with similar authentication requirements. This silo will hold the Domain Admins group and define the authentication boundaries.
Create an authentication policy: Create the policy that defines the specific authentication rules, including the one-hour TGT lifetime and the restriction allowing sign-in only to domain controllers.
Assign the authentication policy silo to user and computer accounts: Finally, assign the Domain Admins group and the domain controller computer accounts to the authentication policy silo, linking the policy requirements to the actual accounts.
Incorrect Option:
Create a Dynamic Access Control claim type: This is for file server authorization and access control, not for Kerberos authentication restrictions.
Create a Dynamic Access Control central access policy: Also related to file server authorization, not authentication policies for Domain Admins.
Configure the Kerberos Policy settings in Default Domain Policy GPO: While this can modify Kerberos settings, it applies to all users domain-wide, not specifically to Domain Admins. Authentication policies provide targeted control.
Reference:
Microsoft Learn: Authentication Policies and Authentication Policy Silos
Microsoft Documentation: Configure protected accounts
| Page 3 out of 16 Pages |