Topic 1: Describe Artificial Intelligence workloads and considerations
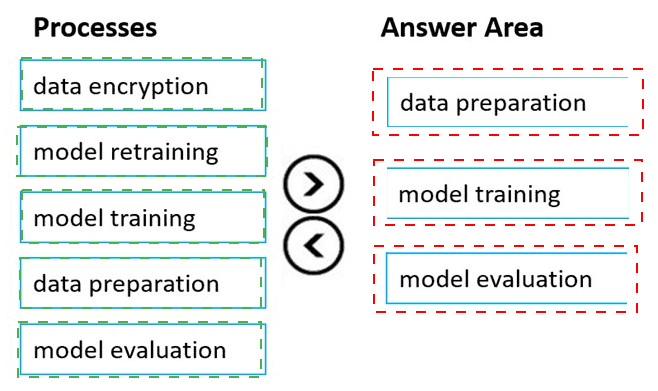
You plan to deploy an Azure Machine Learning model as a service that will be used by client applications.
Which three processes should you perform in sequence before you deploy the model? To answer, move the appropriate processes from the list of processes to the answer area and arrange them in the correct order.
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE Each correct selection is worth one point.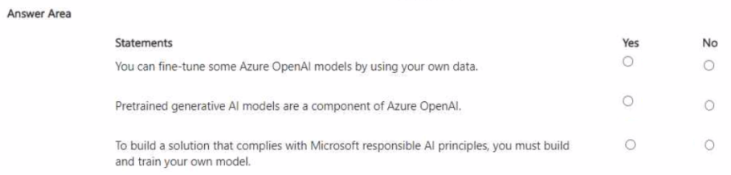
Summary:
This question assesses fundamental knowledge about Azure OpenAI Service's capabilities and its relationship with Microsoft's Responsible AI principles. It tests whether you understand that Azure OpenAI provides powerful, pre-built models that can be customized, and that using these managed services is a primary way to adhere to responsible AI guidelines, as Microsoft has already incorporated these principles into the service's foundation.
Correct Option:
You can fine-tune some Azure OpenAI models by using your own data.
Answer: Yes
Explanation:
This is correct. Azure OpenAI Service supports fine-tuning for certain models like GPT-3.5-Turbo, Babbage-002, and Davinci-002. By providing your own labeled training data, you can customize the model to better understand your specific domain, terminology, and tasks, improving its performance for your unique use case.
Pretrained generative AI models are a component of Azure OpenAI.
Answer: Yes
Explanation:
This is a core true statement. Azure OpenAI Service provides access to powerful, pre-trained generative AI models from OpenAI, such as the GPT series for text and DALL-E for images. These models are the fundamental building blocks of the service, allowing developers to leverage state-of-the-art AI for content generation, summarization, and code generation without building models from scratch.
To build a solution that complies with Microsoft responsible AI principles, you must build and train your own model.
Answer: No
Explanation:
This is false. A key benefit of using Azure OpenAI is that it is built on Microsoft's Responsible AI principles. By using the service, you inherit many of the safety, fairness, and reliability measures Microsoft has implemented. You are responsible for using the models correctly (e.g., filtering inputs and outputs), but you do not need to build your own model from the ground up to be compliant.
Incorrect Option:
You can fine-tune some Azure OpenAI models by using your own data.
Selecting "No" for this statement would be incorrect because fine-tuning is a supported and documented feature for specific model families within the service, allowing for significant customization.
Pretrained generative AI models are a component of Azure OpenAI.
Selecting "No" for this statement would be incorrect. Providing access to these pre-trained models is the primary purpose and core component of the Azure OpenAI Service.
To build a solution that complies with Microsoft responsible AI principles, you must build and train your own model.
Selecting "Yes" for this statement would be incorrect. It misrepresents the shared responsibility model. Using Azure's AI services is, in fact, a recommended path to compliance, as Microsoft handles many foundational responsible AI aspects within the platform.
Select the answer that correctly completes the sentence.
Summary:
This question is about the standard workflow in machine learning for ensuring a model's accuracy is genuine and not biased by the data it was trained on. The process involves dividing the dataset into distinct subsets for different purposes. The key is to use one portion to build the model and a separate, untouched portion to evaluate its performance on new, unseen data.
Correct Option:
model training
This is the correct term that completes the sentence. The standard practice is to use one portion of the dataset (the training set) to prepare and train the machine learning model. The model learns the patterns from this data. The retained balance of the dataset (the test set) is then used to verify the results and evaluate how well the model generalizes to unseen information.
Incorrect Option:
feature engineering
Feature engineering is the process of using domain knowledge to create or modify input variables (features) that make machine learning algorithms work better. While it is a crucial step in model preparation, it is not the specific term for the portion of data used to build the model. Data splitting happens before or after feature engineering, but the portion used for building is called the training set.
time constraints
Time constraints refer to limitations in project timelines. They are an external factor that might influence how you manage your data or model training (e.g., by limiting hyperparameter tuning), but they are not a portion of a dataset used for a specific purpose in the ML workflow.
features enclosed test
This phrase is not a standard term in machine learning. It appears to be a distractor that incorrectly combines the concepts of "features" and "test set."
MLflow models
MLflow is an open-source platform for managing the machine learning lifecycle, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. "MLflow models" refers to the packaged model format, not a portion of a dataset.
Reference:
Split data for machine learning in Azure Machine Learning
Select the answer that correctly completes the sentence.
Summary:
This question tests your understanding of fundamental machine learning terminology. In a dataset used for training a model, the individual data points (rows) are described by their characteristics or attributes. These attributes are the input variables that the model uses to learn patterns and make predictions. The specific term for these input variables is distinct from the output the model is trying to predict.
Correct Option:
features.
In a machine learning model, the input data used to make a prediction are called features. These are the independent, measurable variables or characteristics that describe each instance in the dataset. For example, in a model predicting house prices, features would include square footage, number of bedrooms, and postal code. The model learns the relationship between these features and the target output.
Incorrect Option:
functions.
Functions are blocks of code that perform a specific task. While machine learning models themselves can be thought of as complex functions (mapping inputs to outputs), the input data passed into the model are not called "functions." This term refers to the operational logic, not the data.
labels.
Labels are the outputs or the answers in a supervised learning scenario. They are the dependent variable that the model is trained to predict. For instance, in a disease prediction model, the "disease" or "no disease" outcome is the label. The inputs used to predict that label are the features, not the labels themselves.
instances.
An instance (or sample) refers to a single row or individual example within the entire dataset. An instance is comprised of a set of features and, in supervised learning, an associated label. The term "instance" refers to the whole data point, not specifically to the input data within it.
Reference:
What is machine learning? - Key terminology
To complete the sentence, select the appropriate option in the answer area.

Summary:
This scenario describes the process of converting spoken language (the audio from the session) into written text (the subtitles). This is a core task in AI that involves analyzing the audio stream, identifying the words being spoken, and transcribing them accurately. The key is the conversion from speech to text.
Correct Option:
speech recognition.
Speech recognition, also known as speech-to-text, is the technology that converts spoken audio into written text. The process involves receiving the audio input from the presenter's speech, processing it to identify phonemes and words, and then outputting the corresponding text as subtitles. This is the exact function described in the question.
Incorrect Option:
sentiment analysis.
Sentiment analysis is used to identify and categorize the subjective opinions or emotions within text (e.g., determining if a product review is positive or negative). It analyzes the meaning and tone of existing text, but it does not perform the initial conversion of audio into that text.
speech synthesis.
Speech synthesis, also known as text-to-speech, is the opposite of the described process. It converts written text into spoken audio. An example would be an audiobook being read by a computer voice. The question involves turning speech into text, not text into speech.
translation.
Translation involves converting text or speech from one language to another (e.g., from English to Spanish). While a transcription system could be combined with a translation service to create subtitles in a different language, the core action described—converting the spoken session into text—is speech recognition itself.
Reference:
What is speech recognition? - Azure AI services
You have an app that identifies birds in images. The app performs the following tasks:
* Identifies the location of the birds in the image
* Identifies the species of the birds in the image
Which type of computer vision does each task use? To answer, select the appropriate
options in the answer area.
NOTE: Each correct selection is worth one point.
Summary:
This question distinguishes between two fundamental computer vision tasks: locating objects versus categorizing them. The first task requires identifying where multiple objects are within an image, which is a spatial localization problem. The second task requires identifying what each object is, which is a categorization problem. These are handled by different, specialized types of models.
Correct Option:
Locate the birds: Object detection
Object detection is the correct choice for locating birds. This technology is designed to identify and locate multiple instances of objects within an image by drawing bounding boxes around them. It answers the question "Where are the birds?" by providing the coordinates for each bird found in the picture.
Identify the species of the birds: Image classification
Image classification is the correct choice for identifying the species. This technology assigns a single label or category to an entire image. In this case, if an image contains a single bird, a classification model would label it as "Northern Cardinal" or "Bald Eagle." For multiple birds, object detection would first locate each one, and then an image classification model could be applied to each individual bounding box to identify its species.
Incorrect Option:
Automated Captioning
Automated captioning (or dense captioning) generates a descriptive text sentence for an image or a region, such as "a red bird sitting on a branch." It is not used for the precise, coordinate-based localization of objects (task 1) nor for assigning a simple species label (task 2). It provides a richer linguistic description than what is required here.
Optical Character Recognition (OCR)
OCR is used exclusively for detecting and reading text within images, such as the writing on a sign or a license plate. It has no capability to locate or identify natural objects like birds.
Reference:
What is computer vision? - Image classification
What is computer vision? - Object detection
| Page 7 out of 33 Pages |