Topic 5: Describe features of conversational AI workloads on Azure
Select the answer that correctly completes the sentence.

Explanation
The scenario describes ensuring a system behaves correctly when input data is incomplete or anomalous. This directly relates to building robust, dependable AI systems that perform safely even in unexpected or edge‑case conditions—the core aim of the reliability and safety principle. Handling missing or unusual values prevents the system from making erroneous or harmful predictions, thereby maintaining its operational integrity and safety.
Correct Option
Reliability and safety:
This responsible AI principle focuses on ensuring AI systems operate consistently, safely, and as intended across a wide range of conditions, including when input data is imperfect. Properly managing missing or unusual data is a fundamental engineering practice within this principle to avoid unreliable or unsafe outputs.
Incorrect Options
Inclusiveness:
This principle aims to address bias and ensure AI systems benefit all people equitably, regardless of background or ability. It does not specifically address data‑quality handling.
Privacy and security:
This principle concerns protecting data from unauthorized access and ensuring user privacy. While important, it is not about managing data anomalies for system reliability.
Transparency:
This principle focuses on making AI systems understandable and their decisions explainable to users. It does not directly deal with the technical handling of missing or unusual input values.
Reference
Microsoft’s Responsible AI principles document defines reliability and safety as requiring that AI systems behave reliably and safely under all conditions, including when processing imperfect or unexpected data. Techniques like data validation and robust error handling are implementations of this principle.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Explanation
This set of statements tests fundamental knowledge of generative AI and language models. The answers depend on the core definitions: generative AI creates new content; LLMs are characterized by their vast parameter scale; and generative AI is not exclusively supervised learning—it often uses self‑supervised or unsupervised pre‑training.
Correct Options
Row 1 – Yes:
Generative AI is defined by its ability to create original content—such as text, images, code, or audio—that did not exist before, rather than just analyzing existing data. This is its primary distinction from discriminative AI.
Row 2 – Yes:
The primary distinction between a Large Language Model (LLM) and a Small Language Model (SLM) is the number of parameters (variables). LLMs have billions or trillions of parameters, enabling broad knowledge and complex reasoning, while SLMs have significantly fewer, making them faster and cheaper but with more limited capabilities.
Row 3 – No:
Generative AI is not exclusively a type of supervised learning. While some generative tasks can use supervised fine‑tuning, the foundational training of models like GPT or DALL‑E is typically self‑supervised (predicting the next token in a large corpus) or unsupervised, not reliant on labeled input‑output pairs in the traditional supervised sense.
Incorrect Options
Row 1 – No:
Incorrect. The defining capability of generative AI is novel content generation, not just analysis or classification.
Row 2 – No:
Incorrect. Parameter count is the key differentiating factor, not just training data size or use case.
Row 3 – Yes:
Incorrect. Labeling all generative AI as supervised learning misrepresents its core training methodologies.
Reference
Microsoft Learn AI‑900 materials define generative AI as systems that generate new content. The module on foundation models explains that LLMs are characterized by their massive scale of parameters, and that generative models are often pre‑trained in a self‑supervised manner on vast unlabeled datasets.
Select the answer that correctly completes the sentence.

Explanation
The sentence describes using a random subset of data from a dataset to assess something about the model. In machine learning workflow, a randomly extracted subset of the full dataset is typically held back as a validation (or test) set. This independent subset is not used during training but is used to evaluate the model's performance, check for overfitting, and tune hyperparameters.
Correct Option
Validation:
A validation set is a randomly selected portion of the original dataset that is used to provide an unbiased evaluation of a model fit during the training phase. It is essential for assessing how well the model generalizes to new, unseen data.
Incorrect Options
Algorithms:
These are the mathematical procedures or models (like linear regression, decision trees) used for training. A data subset is not used "for algorithms."
Features:
These are the input variables or attributes used by the model to make predictions. A data subset contains features, but the subset itself is not "for features."
Labels:
These are the target outputs or true values the model is trying to predict in supervised learning. While a validation subset includes labels, the purpose of the subset is not "for labels" but for evaluation.
Reference
Microsoft Learn documentation on "Split data into training and testing sets" explains that data is typically divided into training, validation, and test sets. The validation set is used to tune model parameters and evaluate performance during development to prevent overfitting.
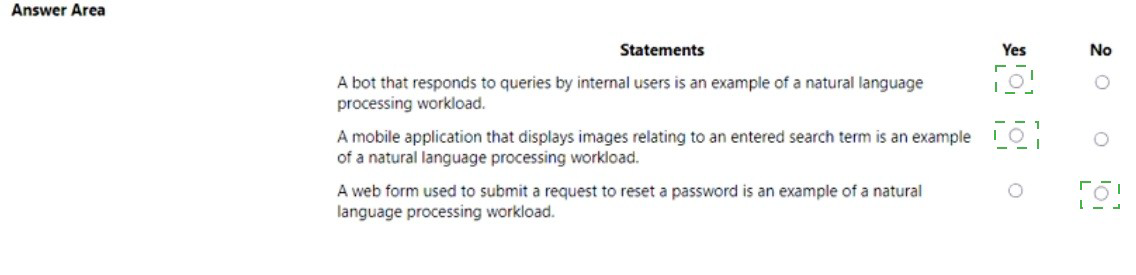
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Explanation
This set tests understanding of what constitutes a natural language processing (NLP) workload. An NLP workload involves AI systems that process, understand, or generate human language. If a system interacts with users using natural language (text or speech), it is an NLP workload. Simple graphical interfaces or image-based tasks without language understanding are not NLP.
Correct Options
Row 1 – Yes:
A bot that responds to user queries must understand the natural language in the query and generate a language‑based response. This is a core example of an NLP workload (often using services like Azure AI Language or the Bot Service with QnA).
Row 2 – Yes:
A mobile app that takes a search term (a text query in natural language) and returns relevant images involves understanding the user's intent and the semantics of the search query – an NLP task. The image retrieval itself is a separate step, but the query processing is NLP.
Row 3 – No:
A standard web form for password reset is a graphical user interface (GUI) form. The user fills out fields manually; there is no AI interpreting natural language. This is a traditional software form, not an NLP workload.
Incorrect Options
Row 1 – No:
Incorrect. Any conversational bot that processes user text or speech is definitively an NLP application.
Row 2 – No:
Incorrect. Processing a textual search query to understand user intent is a fundamental NLP task, even if the output is non‑textual (images).
Row 3 – Yes:
Incorrect. A static web form does not use AI to understand language; it is a simple data‑entry mechanism.
Reference:
Microsoft Learn AI‑900 content defines natural language processing as the AI capability that enables applications to understand, interpret, and respond to human language. Examples given include chatbots, search query understanding, translation, and sentiment analysis—all of which involve processing natural language input.
| Page 3 out of 33 Pages |