Topic 3: Misc. Questions
You have an Azure subscription that contains an Azure Al Content Safety resource.
You are building a social media app that will enable users to share images.
You need to configure the app to moderate inappropriate content uploaded by the users.
How should you complete the code? To answer, select the appropriate options in the answer area.
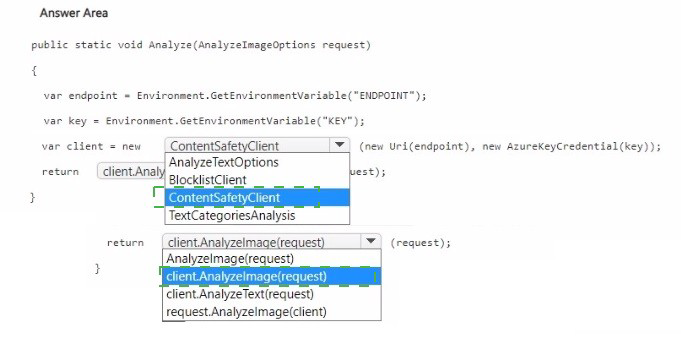
NOTE: Each correct selection is worth one point.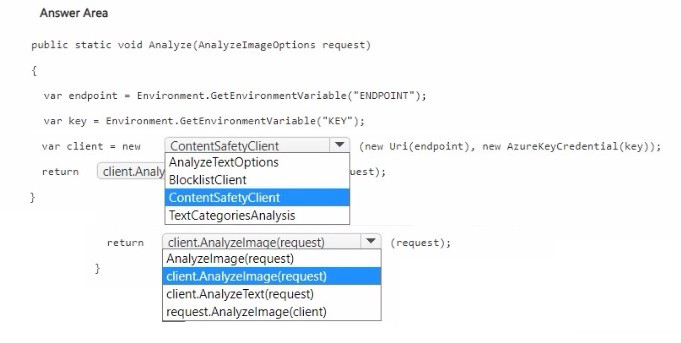
Explanation:
Azure AI Content Safety provides image moderation via the AnalyzeImage method. You need to instantiate a ContentSafetyClient with the endpoint and key, then call client.AnalyzeImage(request) where request is an AnalyzeImageOptions object containing the image data.
Correct Options:
First blank (after new): ContentSafetyClient
The ContentSafetyClient is the main client class for interacting with Azure AI Content Safety. It requires an endpoint URI and an AzureKeyCredential object for authentication.
Second blank (return statement): client.AnalyzeImage(request)
The AnalyzeImage method analyzes an image for objectionable content (hate, sexual, violence, self-harm). It accepts an AnalyzeImageOptions object containing the image (as a stream or URL) and returns an AnalyzeImageResult.
Why Other Options Are Incorrect:
First blank alternatives:
AnalyzeTextOptions – This is a request options class for text moderation, not for creating a client.
BlocklistClient – A client for managing custom blocklists, not for image moderation.
TextCategoriesAnalysis – This is a result type, not a client class.
Second blank alternatives:
AnalyzeImage(request) – Missing client. prefix; would not reference the client instance.
client.AnalyzeText(request) – For text moderation, not images.
request.AnalyzeImage(client) – Incorrect method invocation; AnalyzeImage is a method of the client, not the request.
Reference:
Microsoft Learn: "Azure AI Content Safety – Image moderation" – Use ContentSafetyClient.AnalyzeImage.
You have an app that uses the AI Language custom question answering service.
You need to ad alternatives for the word testing by using the Authoring API.
How should you complete the JSON payload? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Explanation:
In custom question answering, synonyms (alternate phrasings) are defined within the alterations array. Each alteration contains a phrases array (synonyms) where you list alternative words or phrases that should be treated as equivalent (e.g., "testing", "T-rials", "Evaluate"). The value field is not used; the correct structure is phrases.
Correct Options:
First blank (instead of "value"): phrases
The phrases array holds the list of synonyms/alternatives. For example, "phrases": ["testing", "T-rials", "Evaluate"]. This tells the question answering service that these words are equivalent.
Second blank (array name): phrases (or the array itself should contain the alternative words)
The array within phrases contains the synonym strings. The example shows "T-rials" and "Evaluate" as alternatives for "testing".
Why Other Options Are Incorrect:
"synonyms" – Not the correct property name. The API uses phrases within alterations.
"value" – Not a valid property for the Authoring API's synonym/alteration definition.
The nested structure with "value": [...] is incorrect.
Reference:
Microsoft Learn: "Custom question answering – Authoring API" – Use alterations array with phrases to define synonyms.
You develop an app in O named App1 that performs speech-to-speech translation.
You need to configure App1 to translate English to German.
How should you complete the speechTransiationConf ig object? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Explanation:
To configure speech-to-speech translation from English to German, you need to set the source language (what the user speaks) using speechRecognitionLanguage to "en-US", and add the target language (what to translate into) using addTargetLanguage with "de". The speechSynthesisLanguage is optional as it defaults to the target language.
Correct Options:
First blank (after translationConfig.): speechRecognitionLanguage
This property sets the language of the incoming speech audio. For English (US), set it to "en-US". The speech recognizer will listen for English and convert it to text before translation.
Second blank (assigned value): "en-US"
The value assigned to speechRecognitionLanguage is the locale code for English (United States). This matches the source language of the user's speech.
Third blank (after translationConfig.): addTargetLanguage
This method adds a target language for translation. For German, you call addTargetLanguage("de"). This adds German as an output language.
Fourth blank (value for target language): "de"
"de" is the locale code for German. This tells the translation service to translate the recognized English text into German. For speech-to-speech translation, the service will also synthesize German speech output.
Why Other Options Are Incorrect:
speechSynthesisLanguage – Would set the output speech language, but addTargetLanguage is preferred and automatically handles synthesis.
voiceName – Specifies a particular voice for speech synthesis, not the translation target language.
Reference:
Microsoft Learn: "Speech Translation – Configuration" – Set SpeechRecognitionLanguage for source, use AddTargetLanguage for target(s).
You have an Azure subscription that contains an Azure Al Foundry Content Safety resource named resource1.
You are building an app that will analyze text by using resource1.
You need to identify text that contains hateful content.
How should you complete the code? To answer, select the appropriate options in the answer area.
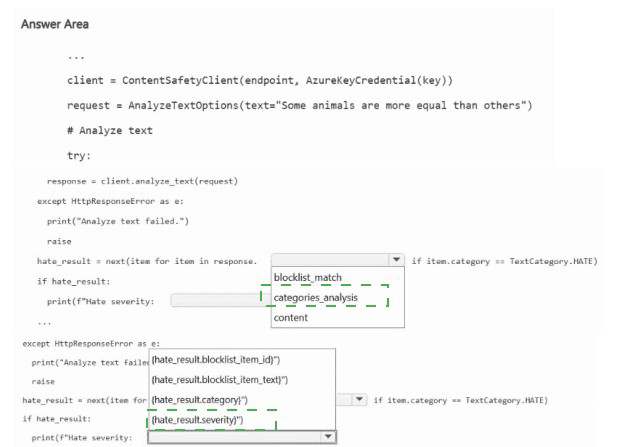
NOTE: Each correct selection is worth one point.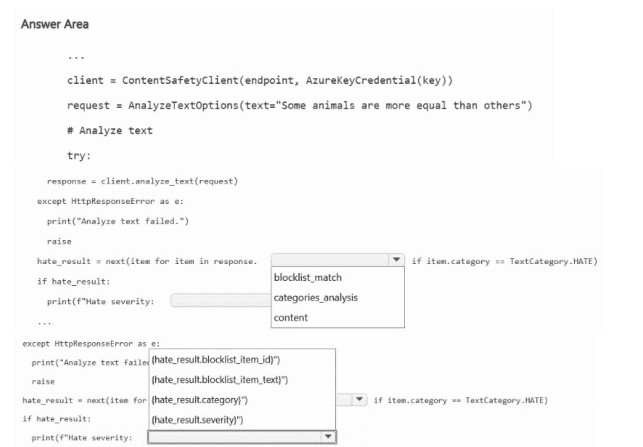
Explanation:
The Content Safety SDK's analyze_text method returns a response containing a categories_analysis list. Each category (hate, sexual, violence, self-harm) has a severity level. To identify hateful content, you iterate through categories_analysis to find the item where category equals "Hate".
Correct Options:
First blank (after response.): categories_analysis
The AnalyzeTextResult object contains a categories_analysis property, which is a list of TextCategoriesAnalysis objects. Each object has category (e.g., "Hate", "Sexual", "Violence", "SelfHarm") and severity (0-7 scale).
Second blank (in the condition): category == "Hate"
To filter for hate content, you check if item.category == "Hate". This identifies the hate category analysis result. The other options (blocklist_match, content, etc.) are not relevant for severity filtering.
Third blank (print statement): item.severity
After identifying the hate category result, you print its severity level. The severity indicates how severe the hateful content is (0 = safe, 7 = most severe). item.severity is the correct property.
Why Other Options Are Incorrect:
First blank alternatives:
blocklist_match – Contains results from custom blocklist matching, not category severity analysis.
content – Not a property of the response object.
Second blank alternatives:
blocklist_match – For custom term lists, not category filtering.
content – Not applicable.
Third blank alternatives:
blocklist_match – Returns blocklist match details, not severity.
content – Not a property of the category analysis object.
Reference:
Microsoft Learn: "Azure AI Content Safety – Analyze text" – Response contains categories_analysis list with category and severity.
You have 100,000 images.
You need to build an app that will perform the following actions:
• Identify road signs in the images and extract the text on the signs.
• Analyze the text to identify well-known locations.
The solution must minimize development effort.
What should you use for each action? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Explanation:
To extract text from images (road signs), Azure AI Vision provides OCR (Read API) that works out-of-the-box. For analyzing extracted text to identify well-known locations (e.g., city names, landmarks), Azure AI Language provides named entity recognition (NER) that identifies Location entities without training.
Correct Options:
First action (extract the text from signs): Azure AI Vision
Azure AI Vision's Read API (OCR) extracts printed text from images. It is pre-built, requires no training, and handles various fonts, angles, and lighting conditions. This minimizes development effort compared to custom solutions.
Second action (identify well-known locations): Azure AI Language
Azure AI Language provides pre-built Named Entity Recognition (NER) that identifies entities including Location (cities, countries, landmarks). The extracted text from signs can be sent to the Language service to identify location names without custom training.
Why Other Options Are Incorrect:
First action alternatives:
Azure AI Document Intelligence – Also extracts text but is optimized for structured documents (forms, invoices). Overkill for simple text extraction from signs.
Azure AI Language – Works on text input, not images. Cannot extract text directly.
Azure AI Search – A search service, not a text extraction service.
Second action alternatives:
Azure AI Search – Can index and search text but does not perform entity recognition or location identification.
Azure AI Document Intelligence – Extracts structured data from documents, not for identifying locations in text.
Azure AI Vision – Can detect objects and read text but does not identify well-known locations from text.
Reference:
Microsoft Learn: "Azure AI Vision – OCR" – Extract printed text from images.
| Page 9 out of 40 Pages |