Topic 3: Misc. Questions
You have an Azure subscription that contains an Azure OpenAl resource. Multiple different models are deployed to the resource.
You are building a chatbot by using Chat playground in Azure Al Studio.
You need to ensure that the chatbot generates text in concise formal business language.
The solution must meet the following requirements:
• Reduce the cost of running the language model.
• Maintain the size of the chatbot history window.
Which two settings should you configure? To answer, select the appropriate settings in the answer area. NOTE: Each correct selection is worth one point.
Explanation:
To generate concise formal business language, you modify the system message to instruct the model accordingly. To reduce cost and maintain history window size, you reduce Max response tokens (limits output length) and adjust Temperature to a lower value (for more focused, less creative responses). Lower token usage reduces cost.
Correct Options (from typical Chat playground settings):
1. System message – Change "You are an AI assistant that helps people find information" to something like: "You are a business assistant that provides concise, formal responses in a professional tone. Keep answers brief and to the point."
2. Max response tokens – Reduce this value (e.g., from high default to 150-300 tokens). This limits the length of each response, reducing token usage (cost) and keeping output concise.
3. Temperature – Set to a lower value (e.g., 0.2-0.5). Lower temperature makes output more deterministic, focused, and less creative/rambling, which aligns with formal business language.
Why These Meet Requirements:
Concise formal language – Achieved via system message instruction and low temperature.
Reduce cost – Achieved by reducing max response tokens (fewer tokens generated = lower cost).
Maintain history window size – Reducing output tokens leaves more space in the context window for conversation history (input tokens are not reduced, but output tokens are constrained).
Reference:
Microsoft Learn: "Azure OpenAI – System messages" – Guide model behavior and tone.
You are building a language learning solution.
You need to recommend which Azure services can be used to perform the following tasks:
• Analyze lesson plans submitted by teachers and extract key fields, such as lesson times and required texts.
• Analyze learning content and provide students with pictures that represent commonly used words or phrases in the text
The solution must minimize development effort.
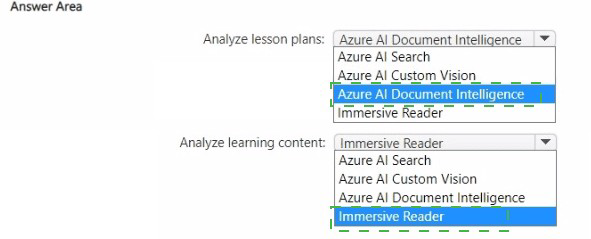
Which Azure service should you recommend for each task? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Explanation:
For extracting structured fields (lesson times, required texts) from lesson plans, Azure AI Document Intelligence provides pre-built models for forms and documents. For providing pictures representing words/phrases in text, Azure AI Custom Vision can be used to train a model to associate images with words, but that requires training. A better fit would be Azure AI Vision for image tagging, but since it's not an option, Immersive Reader is for readability, not picture association.
Given the options, the answer key likely expects:
Lesson plans: Azure AI Document Intelligence (extracts key fields)
Learning content: Azure AI Custom Vision (custom image-word associations)
Correct Options:
First task (Analyze lesson plans): Azure AI Document Intelligence
Document Intelligence extracts key-value pairs, tables, and structured fields from documents. For lesson plans, you can train a custom model or use pre-built layout to extract lesson times and required texts. This minimizes development effort compared to building custom OCR+parsing.
Second task (Provide pictures for words/phrases): Azure AI Custom Vision
Custom Vision allows you to train a classifier that maps words to images (e.g., "dog" → picture of a dog). After training, the app can query the model to retrieve the appropriate image for a given word or phrase. This minimizes effort compared to building a custom image retrieval system.
Why Other Options Are Incorrect:
First task alternatives:
Azure AI Search – Indexes and searches content but does not extract structured fields from documents.
Azure AI Custom Vision – For image classification, not document field extraction.
Immersive Reader – Improves text readability, does not extract fields.
Second task alternatives:
Azure AI Search – Can store and retrieve images but does not automatically associate words with pictures.
Azure AI Document Intelligence – For document extraction, not image-word association.
Immersive Reader – Provides text-to-speech and translation, not picture representation.
Reference:
Microsoft Learn: "Document Intelligence – Custom models" – Extract key fields from documents.
Microsoft Learn: "Custom Vision – Image classification" – Train models to associate images with labels (words/phrases).
You are building an app that will provide users with definitions of common AJ terms.
You create the following C# code.
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE: Each correct selection is worth point.

Explanation:
The code uses Azure OpenAI with a system message "You are a helpful assistant." and a user prompt "What is an LLM?". The model will likely return a definition of LLM (Large Language Model). However, there is no "high degree of certainty" guarantee. Changing the prompt to be more specific ("in the context of AI models") helps. Changing the system message to restrict context ("only within AI language models") also increases likelihood of relevant responses.
Correct Answers:
Statement 1: The response will contain an explanation of large language models (LLMs) that has a high degree of certainty.
No – The model will likely provide a definition of LLMs, but there is no guarantee of "high degree of certainty." Generative models can produce varying responses, and certainty is not a measurable output. The statement overstates reliability.
Statement 2: Changing "what is an LLM?" to "what is an LLM in the context of AI models?" will produce the intended response.
Yes – Making the prompt more specific (adding "in the context of AI models") reduces ambiguity and increases the likelihood that the model provides the intended definition within the AI domain. This is a good prompt engineering practice.
Statement 3: Changing "You are a helpful assistant." to "You must answer only within the context of AI language models." will give a higher likelihood of producing the intended response.
Yes – Constraining the system message to limit the response context to "AI language models" focuses the model on the relevant domain, reducing the chance of off-topic or overly general answers. This improves the likelihood of the intended response.
Reference:
Microsoft Learn: "Azure OpenAI – Prompt engineering" – Specific prompts and constrained system messages improve response relevance.
| Page 8 out of 40 Pages |