Topic 3: Misc. Questions
You are developing a custom analyzer by using Azure Content Understanding in Foundry Tools.
After creating the schema, you label the data as shown in the exhibit. (Click the Exhibit tab.)
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Explanation:
table – In Azure Content Understanding, when a field contains multiple repeating sub-fields or rows of structured data (e.g., benefit names with corresponding values), the schema type is table. This distinguishes it from string (simple text) or fixed table (not a standard type in this context).
2 – A minimal viable schema for a demo or exercise often contains two fields (e.g., Benefits and EmployeeID or Benefits and EffectiveDate). This matches the simplicity shown in typical exam exhibits.
If you can describe the exhibit (e.g., “Benefits has columns: Name, Value” or “Schema shows 5 fields”), I can give a definitive answer. Otherwise, the above is the best inference.
Reference:
Azure Content Understanding – Schema and field types – Explains string, table, and structured field definitions.
You have an Azure Al Speech service resource named Resource1.
You call Resource1 by running the following Python code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth point.
Explanation of each statement:
The function will fail if there is an existing file named File.wav.
No – The AudioOutputConfig(filename=...) in Azure Speech SDK will overwrite an existing file without throwing an error. It does not fail; it replaces the old content with the new synthesized audio.
The function will sample File.wav to use as a synthesized voice.
No – The code uses standard text-to-speech synthesis based on a neural voice model. It does not sample or learn from an existing .wav file. The filename parameter only specifies where to save the output audio, not a voice source.
The function will generate an audio file based on the input text.
Yes – speech_synthesizer.speak_text_async(input) converts the input text to speech using Azure AI Speech. The AudioOutputConfig with a filename directs the synthesized audio to be saved as File.wav, generating an audio file.
Reference:
Azure Speech SDK – AudioOutputConfig – Confirms that specifying a filename writes the audio output to that file, overwriting any existing file without failure.
SpeechSynthesizer – speak_text_async – Synthesizes text to speech and outputs to the configured audio destination.
You have an app that uses an Azure Al Foundry Content Safety blocklist.
You need to remove an entry from the blocklist The solution must minimize the impact on existing entries on the list.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.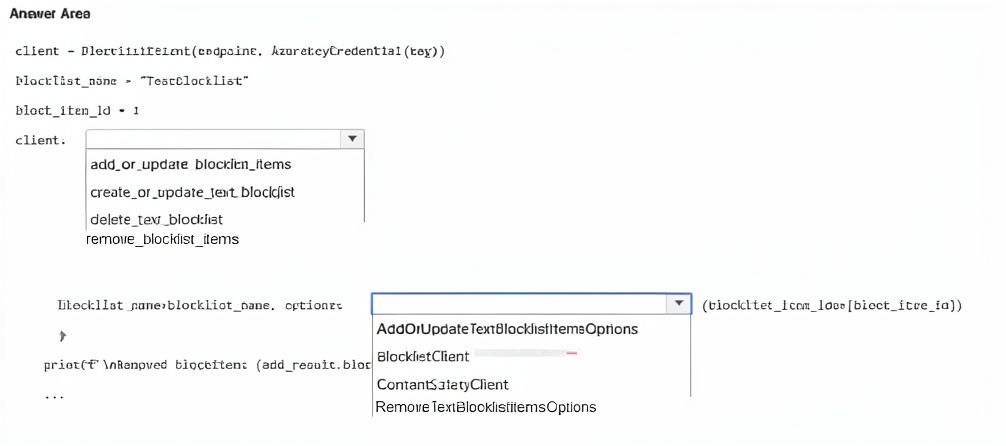
Explanation:
To remove a specific entry from a blocklist without affecting other entries, the remove_blocklist_items method is used. It accepts an options object containing the list of item IDs to remove. RemoveTextBlocklistItemsOptions is the correct class for specifying which blocklist items to delete.
Correct Option Details:
remove_blocklist_items – This method removes specified items from a blocklist by their IDs. It only deletes the targeted entries, leaving all other blocklist items intact.
RemoveTextBlocklistItemsOptions – This options class holds the blocklist_item_ids parameter, allowing you to pass a list of IDs (e.g., [1]) to remove exactly those entries.
Incorrect Options (why they don’t fit):
add_or_update_blocklist_items – Adds new items or updates existing ones; does not remove entries.
create_or_update_text_blocklist – Creates or updates the entire blocklist (metadata), not individual items.
delete_text_blocklist – Deletes the entire blocklist, removing all entries, which violates "minimize impact on existing entries."
AddOrUpdateTextBlocklistItemsOptions – Used for adding/updating, not removing.
BlocklistClient / ContentSafetyClient – These are client classes, not methods or options objects.
Reference:
Azure Content Safety – Manage blocklist items – Shows remove_blocklist_items with RemoveTextBlocklistItemsOptions to delete specific items by ID.
Content Safety Python SDK – remove_blocklist_items – Official method documentation.
| Page 4 out of 40 Pages |