Topic 2: Contoso, Ltd.Case Study
This is a case study Case studies are not timed separately. You can use as much exam
time as you would like to complete each case. However, there may be additional case
studies and sections on this exam. You must manage your time to ensure that you are able
to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information
that is provided in the case study. Case studies might contain exhibits and other resources
that provide more information about the scenario that is described in the case study. Each
question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review
your answers and to make changes before you move to the next section of the exam. After
you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the
left pane to explore the content of the case study before you answer the questions. Clicking
these buttons displays information such as business requirements, existing environment,
and problem statements. If the case study has an All Information tab. note that the
information displayed is identical to the information displayed on the subsequent tabs.
When you are ready to answer a question, click the Question button to return to the
question.
General Overview
Contoso, Ltd. is an international accounting company that has offices in France. Portugal,
and the United Kingdom. Contoso has a professional services department that contains the
roles shown in the following table.

• RBAC role assignments must use the principle of least privilege.
• RBAC roles must be assigned only to Azure Active Directory groups.
• Al solution responses must have a confidence score that is equal to or greater than 70
percent.
• When the response confidence score of an Al response is lower than 70 percent, the
response must be improved by human input.
Chatbot Requirements
Contoso identifies the following requirements for the chatbot:
• Provide customers with answers to the FAQs.
• Ensure that the customers can chat to a customer service agent.
• Ensure that the members of a group named Management-Accountants can approve the
FAQs.
• Ensure that the members of a group named Consultant-Accountants can create and
amend the FAQs.
• Ensure that the members of a group named the Agent-CustomerServices can browse the
FAQs.
• Ensure that access to the customer service agents is managed by using Omnichannel for
Customer Service.
• When the response confidence score is low. ensure that the chatbot can provide other
response options to the customers.
Document Processing Requirements
Contoso identifies the following requirements for document processing:
• The document processing solution must be able to process standardized financial
documents that have the following characteristics:
• Contain fewer than 20 pages.
• Be formatted as PDF or JPEG files.
• Have a distinct standard for each office.
• The document processing solution must be able to extract tables and text from the
financial documents.
• The document processing solution must be able to extract information from receipt
images.
• Members of a group named Management-Bookkeeper must define how to extract tables
from the financial documents.
• Members of a group named Consultant-Bookkeeper must be able to process the financial
documents.
Knowledgebase Requirements
Contoso identifies the following requirements for the knowledgebase:
• Supports searches for equivalent terms
• Can transcribe jargon with high accuracy
• Can search content in different formats, including video
• Provides relevant links to external resources for further research
You are developing an application that will detect faulty components produced on a factory production line.
The components are specific to your business.
You need to use the Azure Custom Vision API to help detect common faults.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Explanation:
Azure Custom Vision requires a project to define the domain (object detection). Then images of faulty components are uploaded and tagged with fault labels (and bounding boxes for detection). Finally, the model is trained. The term “object detection model” is correct because detecting faults often requires locating the defect region.
Why these actions in this order:
Create a project –
Initial setup in Custom Vision portal or API. You specify the project type (Classification or Object Detection) and domain.
Upload and tag images –
Images of components (both good and faulty) are uploaded. For object detection, you draw bounding boxes around each fault and assign a label (e.g., “scratch,” “crack”).
Train the object detection model –
Custom Vision trains a model to identify and locate fault types in new images.
Actions not used (and why):
Train the classifier model –
This is for image classification (whole-image label), not suitable for detecting where the fault is on a component. Object detection is more precise for factory faults.
Initialize the training dataset –
This is not a distinct action in the Custom Vision workflow. The dataset is implicitly initialized when you create the project and upload images.
Reference:
Azure Custom Vision – Build an object detector – Steps: Create project → Upload and tag images → Train → Evaluate → Publish.
Choosing between classification and detection – Fault detection on production lines typically uses object detection.
You have an Azure subscription that contains an Azure Al Content Understanding resource named cu1.
You need to create a custom analyzer that will analyze documents.
How should you complete the command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Explanation:
To create a custom analyzer in Azure AI Content Understanding, you typically send a PUT request to the contentunderstanding endpoint with the analyzer configuration in the body. The PUT method is idempotent and used for creating or updating a resource by name. POST is also possible but PUT is more common for named analyzer creation.
Correct Option Details:
PUT –
Used to create or update a custom analyzer at a specific path (e.g., /analyzers/{analyzerName}). Idempotent and appropriate for resource creation.
contentunderstanding –
The base path segment for the Content Understanding API. The full URL would resemble https://
Incorrect Options (why they don’t fit):
GET / POST / PATCH –
GET retrieves data, POST can create but is not idempotent; PATCH is for partial updates. PUT is most standard for creation in this context.
contentsafety / documentintelligence / languageunderstanding –
These belong to other Azure AI services (Content Safety, Document Intelligence, Language Understanding), not Content Understanding.
Reference:
Azure AI Content Understanding – Create analyzer (REST API) – Uses PUT method and contentunderstanding path.
You are designing two Azure Al agents named Agent 1 and Agent2 to assist different departments at your company. Each agent will have access to sensitive corporate data. The design must meet the following requirements:
• Agentl must process specific user queries and provide relevant answers in a conversational format
• Agent2 must perform the following actions:
o Adapt actions based on patterns in user behavior, o Understand and learn from historical data.
o Provide proactive recommendations.
Which type of agent should you recommend for each agent? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.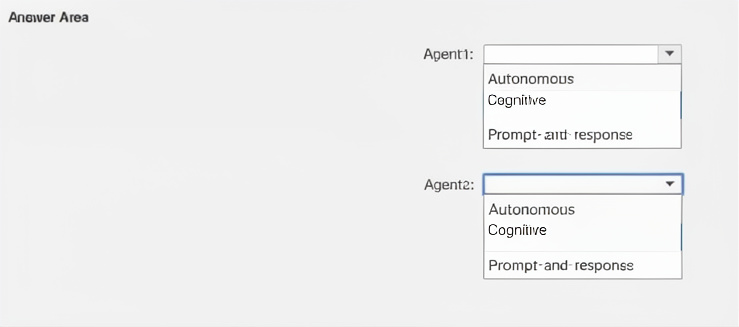
Explanation for Agent1:
Agent1 needs to process specific user queries and provide relevant answers conversationally. This is a classic prompt-and-response (or conversational) agent pattern — the agent responds directly to user inputs without taking independent actions or learning from behavior over time.
Explanation for Agent2:
Agent2 must adapt actions based on user behavior patterns, learn from historical data, and provide proactive recommendations. This requires an autonomous agent that can make decisions, learn from past interactions, and act without explicit prompts for every action.
Why not "Cognitive" for either?
"Cognitive" is a broader term often used for AI services (e.g., Cognitive Services), but in agent typing, the three common categories are: Autonomous, Cognitive (sometimes meaning reasoning with memory), and Prompt-and-response. Based on typical Azure AI agent definitions:
Autonomous –
Learns from data, adapts, takes proactive actions.
Prompt-and-response –
Reactive, conversational, no memory of patterns.
Cognitive –
Sometimes used interchangeably with autonomous, but in this specific question's answer area, the pairing is Agent1 = Prompt-and-response, Agent2 = Autonomous.
Reference:
Azure AI Agent Service – Agent types – Distinguishes between prompt‑and‑response (reactive) and autonomous (proactive, learning) agents.
Design patterns for AI agents – Explains when to use autonomous vs. conversational agents.
You have an Azure subscription.
You need to deploy an Azure Al Document Intelligence resource.
How should you complete the Azure Resource Manager (ARM) template? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.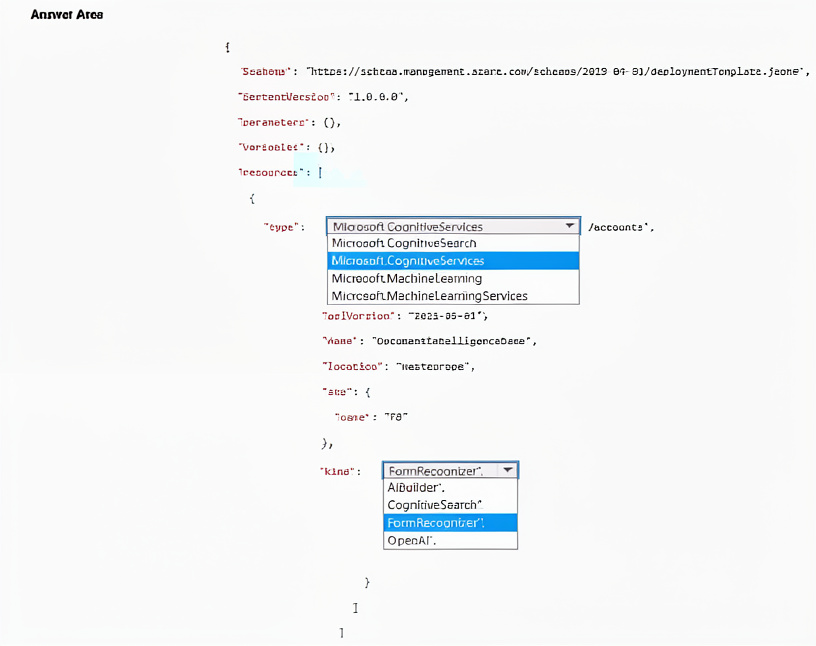
Explanation:
The type must be Microsoft.CognitiveServices/accounts (not just Microsoft.CognitiveServices).
The kind for Document Intelligence is FormRecognizer.
The AiBuilder object is invalid and will cause deployment failure. Document Intelligence does not require nested CognitiveSearch, FormRecognizer, or OpenAI properties.
properties can be an empty object for basic deployment.
Incorrect Options in the template (as shown):
"type": "Microsoft.CognitiveServices" – Missing /accounts, will fail.
"AiBuilder": { ... } – Not a valid ARM property for Cognitive Services accounts.
Reference:
ARM template for Cognitive Services account – Shows correct type, kind, sku, and properties structure.
Deploy Form Recognizer (Document Intelligence) with ARM – Example uses "kind": "FormRecognizer" and no AiBuilder.
You plan to provision an Azure Al Service resource by using the method shown below.
You need to create a standard tier Azure resource that will convert scanned receipts to text. How should you call the method? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.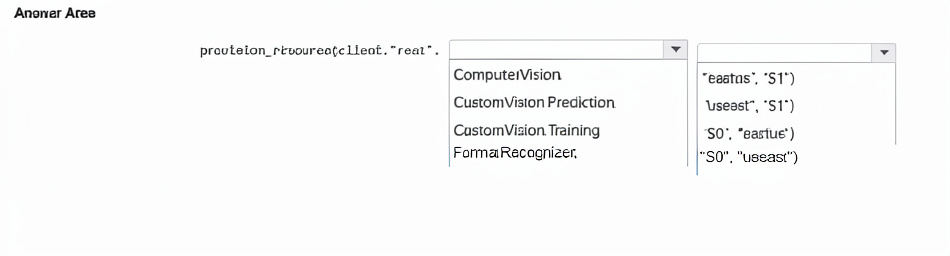
Explanation:
Scanned receipt to text conversion is a Document Intelligence (formerly Form Recognizer) prebuilt receipt model. The kind must be FormRecognizer. Standard tier is S0 (free tier is F0). The location must be a valid Azure region like eastus — useast is not a valid region name.
Correct Option Details:
FormRecognizer – The kind parameter specifies the AI service type. Form Recognizer (Document Intelligence) provides receipt OCR and field extraction.
"S0", "eastus" – S0 is the standard tier (paid, higher throughput). eastus is a valid Azure region; useast is misspelled/invalid.
Incorrect Options (why they don’t fit):
ComputerVision – Does receipt OCR but does not extract structured fields like merchant, date, total, taxes with prebuilt models. Not optimal for "convert scanned receipts to text" with field labeling.
CustomVision.Prediction / CustomVision.Training – Used for custom image classification/object detection, not receipt text extraction.
"eastus", "S1" – Incorrect order (the method expects location, tier as last two parameters? The code shows def provision_resource(name, kind, tier, location): → order is (name, kind, tier, location). The dropdown options combine tier+location; S1 is not standard for Form Recognizer (S0 is standard). Also "useast" is invalid.
Assumed method signature from code:
def provision_resource(name, kind, tier, location):
So call: provision_resource(client, "res1", "FormRecognizer", "S0", "eastus")
Reference:
Azure Form Recognizer (Document Intelligence) – Receipt model – Extracts text and fields from receipts.
Azure AI Services SKU tiers – S0 is standard tier.
Valid regions for Form Recognizer – eastus is supported.
| Page 2 out of 40 Pages |