Topic 3: Misc. Questions
You have an Azure subscription that contains an Azure OpenA1 resource. You configure a model that has the following settings:
• Temperature: 1
• Top probabilities: 0.5
• Max response tokens: 100
You ask the model a question and receive the following response.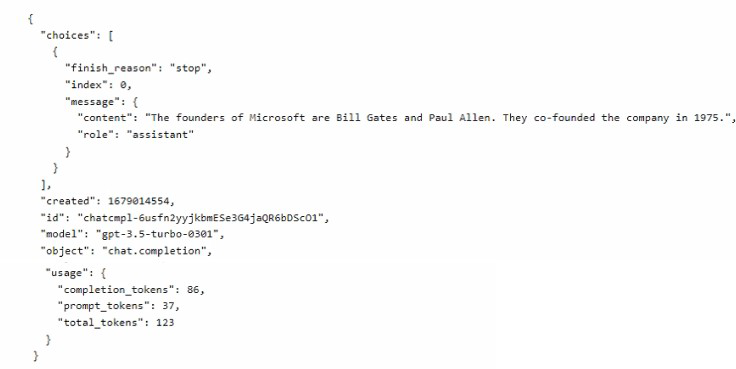
For each of the following statements, select Yes if the statement is true. Otherwise, select
No..
NOTE: Each correct selection is worth point..

Explanation:
The response shows a successful completion with finish_reason: "stop" (natural stop, not truncation). Billing for Azure OpenAI is based on total tokens (prompt + completion). The Max response tokens parameter limits only the completion tokens, not prompt tokens.
Correct Answers:
Statement 1: The subscription will be charged 86 tokens for the execution of the session.
No – The subscription is charged for total tokens (prompt + completion), which is prompt_tokens: 37 + completion_tokens: 86 = 123 tokens. The 86 is only completion tokens. Billing is based on total_tokens (123), not just completion tokens.
Statement 2: The text completion was truncated because the Max response tokens value was exceeded.
No – finish_reason: "stop" indicates the model stopped naturally (reached a stopping condition, not length limit). If Max response tokens (100) had been exceeded, finish_reason would be "length". Since completion_tokens is 86 (<100), truncation did not occur.
Statement 3: The prompt_tokens value will be included in the calculation of the Max response tokens value.
No – Max response tokens limits only the completion tokens (generated output). It does not include prompt_tokens. The prompt tokens are fixed and billed separately but do not count against the Max response tokens limit.
Reference:
Microsoft Learn: "Azure OpenAI – Tokens and billing" – Total tokens = prompt + completion; max_tokens limits completion only.
You have a chatbot that uses Azure OpenAI to generate responses.
You need to upload company data by using Chat playground. The solution must ensure that the chatbot uses the data to answer user questions.
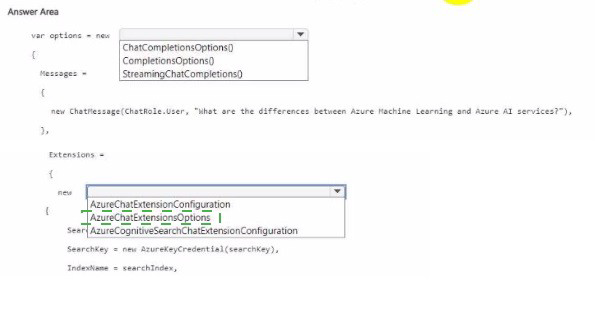
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.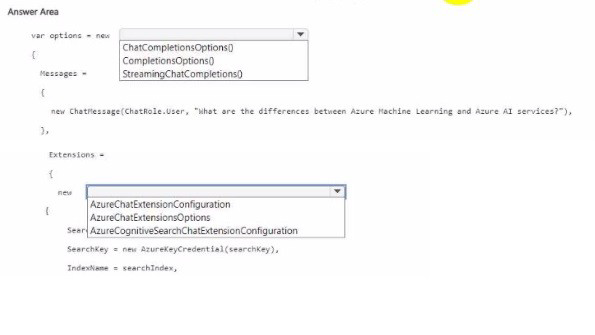
Explanation:
To use company data (from Azure Cognitive Search) with Azure OpenAI in the Chat playground, you configure ChatCompletionsOptions with AzureChatExtensionConfiguration. This enables Retrieval Augmented Generation (RAG), where the model retrieves relevant data from your search index and grounds responses in that data.
Correct Options:
First blank: ChatCompletionsOptions
ChatCompletionsOptions is the class used for chat completion requests with extensions (data sources). It supports adding AzureChatExtensionConfiguration to integrate external data. CompletionOptions is for older non-chat completions; StreamingChatCompletions is a result type, not an options class.
Second blank (Extensions = new { ... }): AzureChatExtensionConfiguration
The extensions collection expects AzureChatExtensionConfiguration objects. Specifically, SearchAzureCognitiveSearchChatExtensionConfiguration (a subclass) is used for Azure Cognitive Search as the data source. This tells Azure OpenAI to retrieve relevant chunks from your search index.
Why Other Options Are Incorrect:
First blank alternatives:
CompletionOptions – Used for legacy text completion (not chat), does not support extensions or messages.
StreamingChatCompletions – This is a response type for streaming results, not a configuration options class.
Extensions alternatives:
AzureChatExtensionsOptions – This is a container class, not the actual extension configuration. You need to add AzureChatExtensionConfiguration objects.
(The third option is incomplete but would be invalid.)
Reference:
Microsoft Learn: "Azure OpenAI – Add your data (RAG)" – Use ChatCompletionsOptions with AzureChatExtensionConfiguration to integrate Cognitive Search.
You are developing a text processing solution.
You develop the following method.
You call the method by using the following code.
GetKeyPhrases(textAnalyticsClient, "the cat sat on the mat");
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Explanation:
The code uses ExtractKeyPhrases on the sentence "the cat sat on the mat". Key phrase extraction identifies important nouns and noun phrases, not all words. Stop words ("the", "on") and verbs ("sat") are typically excluded. The method returns only key phrase strings, not confidence scores.
Correct Answers:
Statement 1: The call will output key phrases from the input string to the console.
Yes – The method iterates through response.Value (key phrases) and writes each to the console using Console.WriteLine(). Assuming the API call succeeds and returns at least one key phrase, output will be produced.
Statement 2: The output will contain the following words: the, cat, sat, on, and mat.
No – Key phrase extraction does not return stop words ("the", "on") or verbs ("sat"). For this sentence, likely output is just "cat" and "mat" (or "cat" and "mat" separately). It will not output all five words as individual key phrases.
Statement 3: The output will contain the confidence level for key phrases.
No – The ExtractKeyPhrases method returns a KeyPhraseCollection containing only the key phrase strings. Confidence scores are not provided for key phrase extraction (unlike entity recognition or sentiment analysis). The code writes keyphrase directly, not any confidence value.
Reference:
Microsoft Learn: "Text Analytics – Key Phrase Extraction" – Returns key phrases as strings, no confidence scores. Stop words and common verbs are filtered out.
You train an Azure Custom Vision object detection model to identify a company's products by using the Retail domain.
You plan to deploy the model as part of a mobile app for Android phones.
You need to prepare the model for deployment.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Explanation:
For mobile deployment (Android), the model must be in a compact domain (e.g., "General (compact)" or "Retail (compact)"). The Retail domain is not compact and cannot be exported. You must change the domain to a compact version, retrain the model, then export it (e.g., to TensorFlow Lite for Android).
Correct Option (in sequence):
Change the model domain.
First, change the project domain from "Retail" to a compact domain compatible with mobile export, such as "General (compact)" or "Retail (compact)". The domain determines export capabilities. This is done in the Custom Vision portal under Project Settings.
Retrain the model.
After changing the domain, retrain the model. Training adjusts the model architecture to the new compact domain. The model will now be optimized for size and speed, suitable for mobile deployment.
Export the model.
Once retrained, export the model to a format compatible with Android (e.g., TensorFlow Lite, ONNX, CoreML). The export option appears after training a compact domain model. Download the exported file for integration into the Android app.
Incorrect Option (not used in sequence):
Test the model. – Testing is optional for validation but not required for preparing the model for deployment. Export can be done without explicit testing.
Reference:
Microsoft Learn: "Custom Vision – Export models for mobile" – Compact domains support export; change domain → retrain → export.
You are building an app that will translate speech by using the Azure Al Language service.
You need configure the app to translate the speech from English to Italian.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.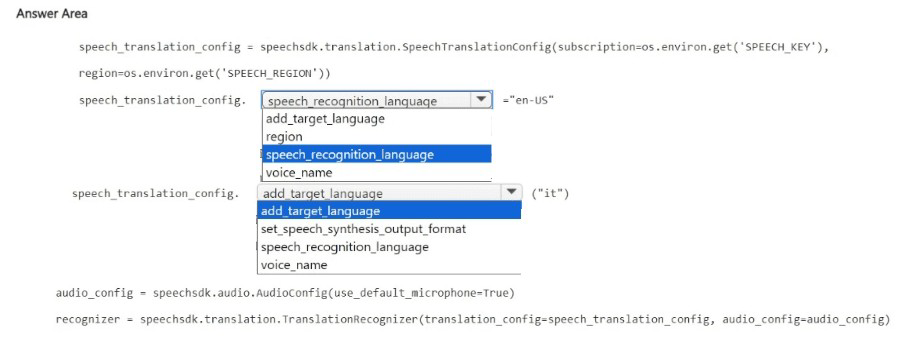
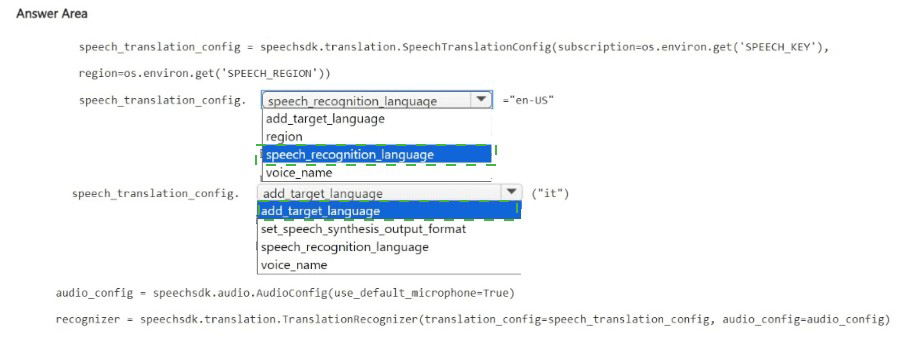
Explanation:
To configure speech translation from English to Italian, set the source language using speech_recognition_language (to "en-US") and add the target language using add_target_language (to "it-IT" or "it"). The add_target_language method adds Italian as a translation target.
Correct Options:
First blank (after speech_translation_config.): speech_recognition_language
This property sets the language of the incoming speech audio. For English, set it to "en-US". The speech recognizer will listen for English and convert it to text before translation.
Second blank (assigned value): "en-US" (implied from the code)
The value assigned to speech_recognition_language should be the locale code for English (United States).
Third blank (after speech_translation_config.): add_target_language
This method adds a target language for translation. For Italian, you would call add_target_language("it-IT") or add_target_language("it"). The method adds Italian as an output language.
Fourth blank (value for target language): "it" or "it-IT" (not explicitly shown in the answer area options, but implied)
Why Other Options Are Incorrect:
For the first blank:
add_target_language – This is for setting target languages, not the source language.
region – This is set in the SpeechTranslationConfig constructor, not as a property here.
voice_name – This specifies the voice for speech synthesis output, not the source language.
For the third blank:
set_speech_synthesis_output_format – This sets the audio output format (e.g., raw PCM, MP3), not the translation target.
speech_recognition_language – Already used for source language; cannot be used for target.
voice_name – Sets the voice for synthesis, not the translation language.
Reference:
Microsoft Learn: "Speech SDK – Translation recognizer" – Use speech_recognition_language for source, add_target_language for target(s).
| Page 14 out of 40 Pages |