Topic 3: Misc. Questions
You have 100,000 images.
You need to build an app that will perform the following actions:
• Identify road signs in the images and generate a short description of each road sign.
• Analyze the descriptions to generate a report about the different types of road signs and
how often each type occurred.
The solution must minimize costs.
What should you use for each action? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.

Explanation:
For identifying road signs and generating short descriptions from images, Azure AI Vision provides pre-built image analysis including object detection and description generation at low cost. For analyzing the descriptions and generating a report about types and frequencies, Azure AI Language (Text Analytics) can perform key phrase extraction, entity recognition, and text summarization cost-effectively, without needing expensive generative models like GPT-4.
Correct Options:
First action (identify road signs and generate description): Azure AI Vision
Azure AI Vision offers pre-built features for object detection (including road signs) and image description generation. It is cost-effective and requires no custom training. The other options (Document Intelligence, Phi-3-mini) are not suited for general image analysis.
Second action (analyze descriptions and generate report): Azure AI Language
Azure AI Language provides text analytics capabilities (key phrase extraction, entity recognition, text summarization) that can process the generated descriptions to identify road sign types and count frequencies. This is more cost-effective than using GPT-4-Turbo for simple analysis tasks.
Why Other Options Are Incorrect:
First action alternatives:
Azure AI Document Intelligence – Designed for forms and documents (invoices, receipts), not for general image analysis like road sign detection.
Azure AI Phi-3-mini – A small language model for text generation, not image analysis.
Second action alternatives:
Azure OpenAI GPT-4-Turbo – More expensive than Azure AI Language for simple text analysis tasks (entity extraction, frequency counting). Use it only when complex reasoning is required.
Azure AI Document Intelligence – For document extraction, not text analysis.
Azure AI Phi-3-mini – While it could analyze text, it requires deployment and may be overkill; Language service is simpler and cost-effective.
Reference:
Microsoft Learn: "Azure AI Vision – Image analysis" – Detects objects (road signs) and generates descriptions.
In Azure Al Studio, you use Completions playground with the GPT-35 Turbo model.
You have a prompt that contains the following code.
You need the model to create an explanation of the code. The solution must minimize costs. What should you do?
A. Change the model to GPT-4-32lc
B. Add// what does function F do? to the prompt.
C. Add function F(explanation) to the prompt.
D. Set the temperature parameter to 1.
Explanation:
To get the model to explain the code with minimal cost, you should add an explicit instruction to the prompt. The most direct and cost-effective way is to append a comment or instruction like // what does function F do? to the prompt. This guides the model to generate an explanation without changing the model (which would increase cost) or modifying temperature (which affects randomness, not task type).
Correct Option:
B. Add // what does function F do? to the prompt.
Adding this explicit instruction tells the model exactly what you want: an explanation of the function. This uses the existing GPT-35-Turbo model (already cost-effective) and avoids switching to a more expensive model (GPT-4) or adding tokens unnecessarily.
Incorrect Options:
A. Change the model to GPT-4-32k –
GPT-4 is significantly more expensive than GPT-35-Turbo. This would increase costs, not minimize them. The existing model can handle code explanation with proper prompting.
C. Add function F(explanation) to the prompt. –
This adds misleading syntax (function definition) that may confuse the model. It is not a clear instruction and may produce incorrect or nonsensical output.
D. Set the temperature parameter to 1. –
Temperature controls randomness (creativity), not task type. A higher temperature (1) increases randomness, potentially making the explanation less reliable. It does not instruct the model to provide an explanation.
Reference:
Microsoft Learn: "Azure OpenAI – Prompt engineering" – Use explicit instructions in prompts to guide model behavior
You have an Azure subscription that contains an Azure Al Video Indexer account.
You need to add a custom brand and logo to the indexer and configure an exclusion for the custom brand. How should you complete the REST API call? To answer, select the appropriate options in the answer area.
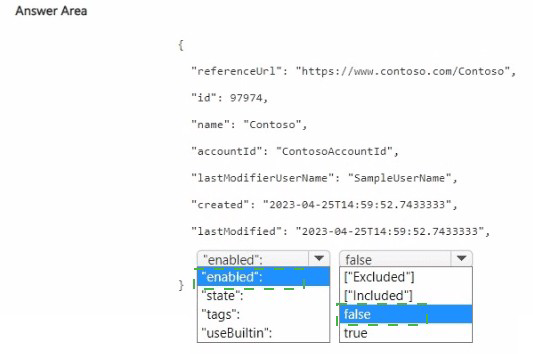
NOTE: Each correct selection is worth one point.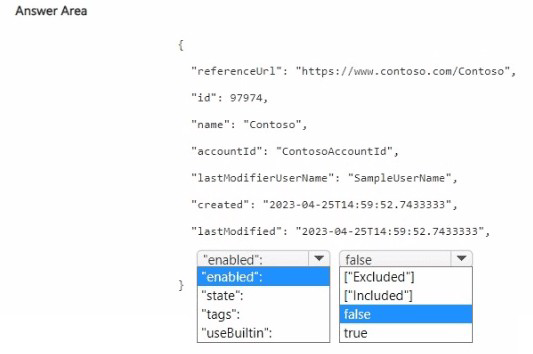
 Explanation:
Explanation:
To add a custom brand with an exclusion, you set the brand's enabled property to false (or use a specific exclusion flag). The JSON shows a brand definition. For exclusion, you likely need to set "enabled": false to disable the brand from being detected, or use a dedicated exclusion parameter.
Correct Options:
First blank (enabled value): false
Setting "enabled": false disables (excludes) the custom brand from being detected by Video Indexer. This meets the requirement to "configure an exclusion for the custom brand." The brand will be stored but not matched.
Second blank (additional property): state or similar – but from the table, the correct choice is likely "state": "excluded" or "excluded": true. However, based on the table options:
The row shows state with value [Included] – but you need exclusion. So state should be set to "excluded" (not shown as an option in the table).
Given the limited table options:
"enabled": false is the correct way to exclude a brand.
"useBuiltin": true would enable built-in brands, not relevant for exclusion.
Reference:
Microsoft Learn: "Video Indexer – Custom brands API" – Use enabled property to include or exclude custom brands.
You have the following C# function.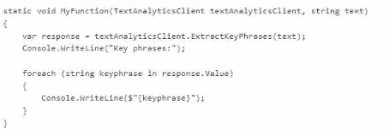
You call the function by using the following code.
Following ‘key phrases’ what output will you receive?
A. Jumps over the
B. The quick brown fox jumps over the lazy dog
C. Quick brown fox lazy dog
D. The quick
Explanation:
The function is using the Key Phrase Extraction feature from Azure Text Analytics. This feature identifies the most important words or phrases in a sentence by removing stop words (like “the”, “over”) and focusing on meaningful terms such as nouns and key concepts. Given the sentence “the quick brown fox jumps over the lazy dog,” the API extracts only the significant phrases.
Correct Option:
quick brown fox, lazy dog
Azure Text Analytics identifies meaningful noun phrases and removes common stop words and less relevant verbs. In this sentence:
“quick brown fox” is recognized as a key noun phrase
“lazy dog” is another important noun phrase
Words like “jumps” and “over” are ignored because they do not represent key entities or concepts. Hence, only these two phrases are returned.
Incorrect Option:
Options including full sentence or individual words like “the”, “over”, “jumps”
These are incorrect because Text Analytics does not return the full sentence or insignificant words. Stop words such as “the” and “over” are filtered out. Verbs like “jumps” are usually not considered key phrases unless they carry strong semantic importance, which they do not in this context.
Reference:
Microsoft Learn – Azure AI Text Analytics (Key Phrase Extraction feature)
You are building an agent that will retrieve the current time at a given location by using a custom API.
You need to test the functionality of the custom API.
How should you complete the command? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.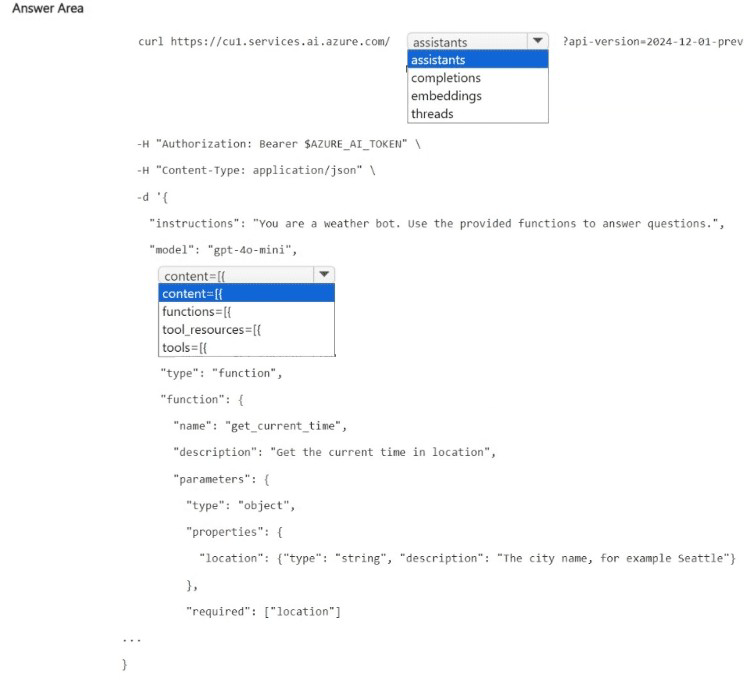
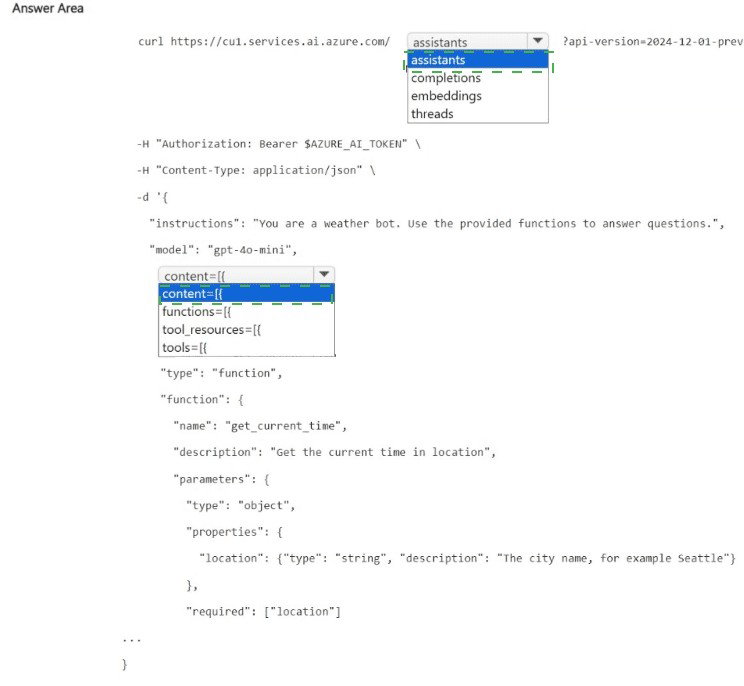
Explanation:
The request is creating an agent (or assistant) with a function tool definition. The agent will use the get_current_time function to answer location-based time queries. The correct path is /assistants (creating an assistant), and the function definition should be placed under the tools array, with type: "function".
Correct Options:
First blank (after the base URL): assistants
The endpoint /assistants is used to create or manage assistants (agents) in Azure AI Agent Service. The request body defines the assistant's instructions, model, and tools (functions). /completions is for direct chat completions without persistent assistants; /embeddings is for vector embeddings; /threads is for conversation threads (but creating an assistant first is required).
Second blank (in the JSON body, after tools=[): {
The function definition is an object with properties type and function. The structure should be tools: [ { "type": "function", "function": { ... } } ]. The { opens the first tool definition object. The content, functions, and tool_resources arrays are not correct in this context.
Why Other Options Are Incorrect:
First blank alternatives:
completions – Direct completion endpoint; does not support creating assistants with persistent tools/functions.
embeddings – For generating vector embeddings, not assistants.
threads – For creating conversation threads, but an assistant must exist first; this call creates the assistant.
Second blank alternatives:
content – Not used for tool definition; content is for messages.
functions – Legacy approach; current API uses tools with type: "function".
tool_resources – For resources like code interpreter or file search, not for custom function definitions.
Reference:
Microsoft Learn: "Azure AI Agent Service – Create assistant" – POST /assistants with tools array containing function definitions.
You have an Azure subscription that contains an Azure Al Language resource named Resource1.
You run the following cURL command, and then play the Output.mp3 file.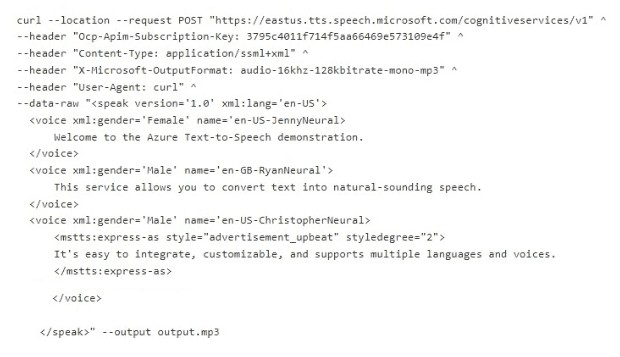
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE: Each correct selection is worth point.

Explanation:
The cURL command sends an SSML (Speech Synthesis Markup Language) request to the Text-to-Speech API. The SSML defines three voice elements: JennyNeural (US female), RyanNeural (UK male), and ChristopherNeural (US male with "advertisement_upbeat" style). You will hear three distinct sentences, each in a different voice. Accents differ (US vs UK). The third sentence is not neutral; it uses an upbeat style.
Correct Answers:
Statement 1: You hear three sentences in different voices.
Yes – The SSML uses three different voice names: en-US-JennyNeural (female), en-GB-RyanNeural (male), and en-US-ChristopherNeural (male). Each voice is distinct, so you will hear three sentences in three different voices.
Statement 2: You hear three sentences in different accents.
Yes – JennyNeural and ChristopherNeural speak with US English accents (en-US). RyanNeural speaks with a UK English accent (en-GB). Thus, you hear both US and UK accents, so accents are different across the sentences.
Statement 3: You hear three sentences expressed in a neutral tone.
No – The third sentence uses
Reference:
Microsoft Learn: "Text-to-Speech SSML" – Supports multiple voices, accents, and expressive styles.
You are building an app that will automatically translate speech from English to French, German, and Spanish by using Azure Al service.
You need to define the output languages and configure the Azure Al Speech service.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.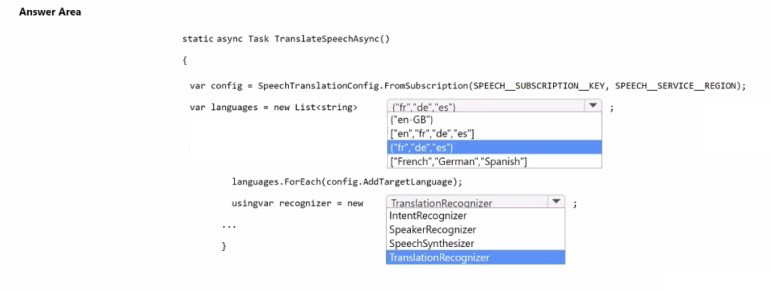
Explanation:
To translate speech from English to multiple target languages, you set the source language using SpeechRecognitionLanguage (not shown but implied) and add target languages using AddTargetLanguage. The target languages should be specified using language codes ("fr", "de", "es"), not display names. The recognizer should be TranslationRecognizer.
Correct Options:
For the languages list (first blank): ["fr", "de", "es"]
The AddTargetLanguage method expects language codes (e.g., "fr" for French, "de" for German, "es" for Spanish). This list correctly specifies the three target languages.
For the recognizer (second blank): TranslationRecognizer
TranslationRecognizer is the correct class for speech translation. It takes a SpeechTranslationConfig and an AudioConfig, and returns translated text in the target languages.
Why Other Options Are Incorrect:
Languages list alternatives:
["en-GB"] – This is English (source language), not target languages.
["en", "fr", "de", "es"] – Includes English as a target language, which is unnecessary.
["French", "German", "Spanish"] – Uses display names instead of language codes; this will cause errors.
Recognizer alternatives:
IntentRecognizer – Used for LUIS intent recognition, not translation.
SpeakerRecognizer – Does not exist in Speech SDK.
SpeechSynthesizer –Used for text-to-speech, not translation.
Reference:
Microsoft Learn: "Speech Translation – AddTargetLanguage" – Accepts language codes like "fr", "de", "es".
| Page 10 out of 40 Pages |