Topic 3, Mix Questions
You have an Azure Data Factory instance named ADF1 and two Azure Synapse Analytics
workspaces named WS1 and WS2.
ADF1 contains the following pipelines:
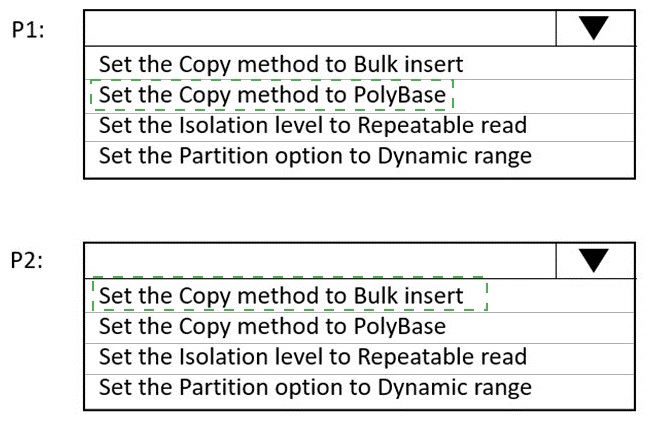
P1: Uses a copy activity to copy data from a nonpartitioned table in a dedicated
SQL pool of WS1 to an Azure Data Lake Storage Gen2 account
P2: Uses a copy activity to copy data from text-delimited files in an Azure Data
Lake Storage Gen2 account to a nonpartitioned table in a dedicated SQL pool of
WS2
You need to configure P1 and P2 to maximize parallelism and performance.
Which dataset settings should you configure for the copy activity if each pipeline? To
answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Data Factory instance that contains two pipelines named Pipeline1 and Pipeline2. Pipeline1 has the activities shown in the following exhibit.
You execute Pipeline2, and Stored procedure1 in Pipeline1 fails.
What is the status of the pipeline runs?
A.
Pipeline1 and Pipeline2 succeeded.
B.
Pipeline1 and Pipeline2 failed.
C.
Pipeline1 succeeded and Pipeline2 failed.
D.
Pipeline1 failed and Pipeline2 succeeded
Pipeline1 and Pipeline2 succeeded.
Explanation:
Activities are linked together via dependencies. A dependency has a condition of one of the
following: Succeeded, Failed, Skipped, or Completed.
Consider Pipeline1:
If we have a pipeline with two activities where Activity2 has a failure dependency on
Activity1, the pipeline will not fail just because Activity1 failed. If Activity1 fails and Activity2
succeeds, the pipeline will succeed. This scenario is treated as a try-catch block by Data
Factory.
Waterfall chart
Description automatically generated with medium confidence
The failure dependency means this pipeline reports success.
Note:
If we have a pipeline containing Activity1 and Activity2, and Activity2 has a success
dependency on Activity1, it will only execute if Activity1 is successful. In this scenario, if
Activity1 fails, the pipeline will fail.
Reference:
https://datasavvy.me/category/azure-data-factory/
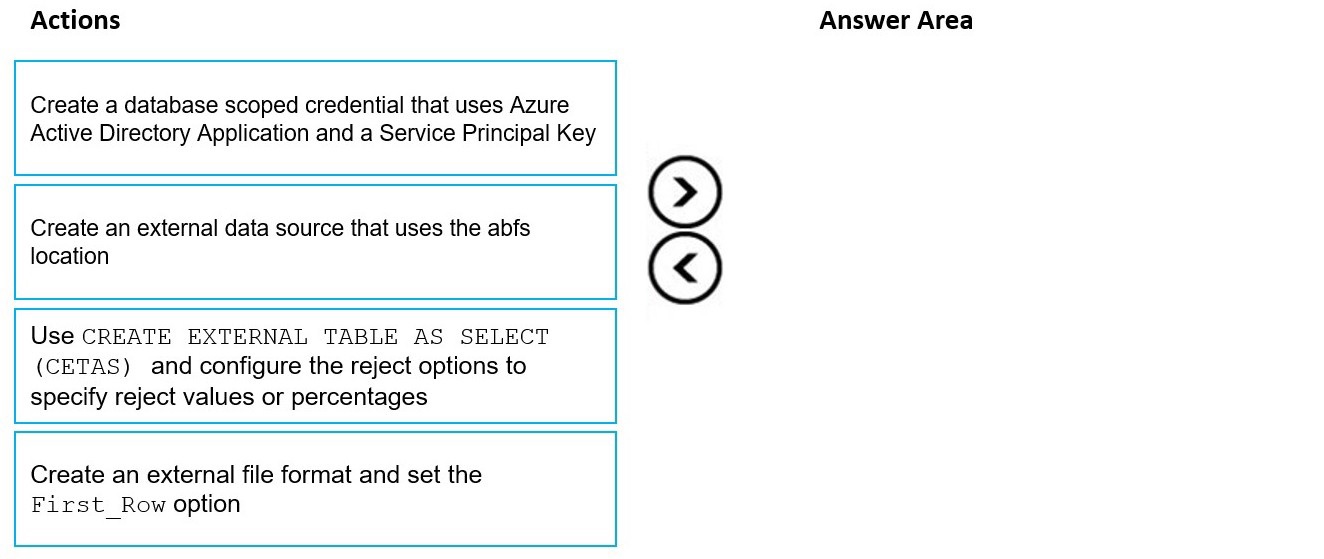
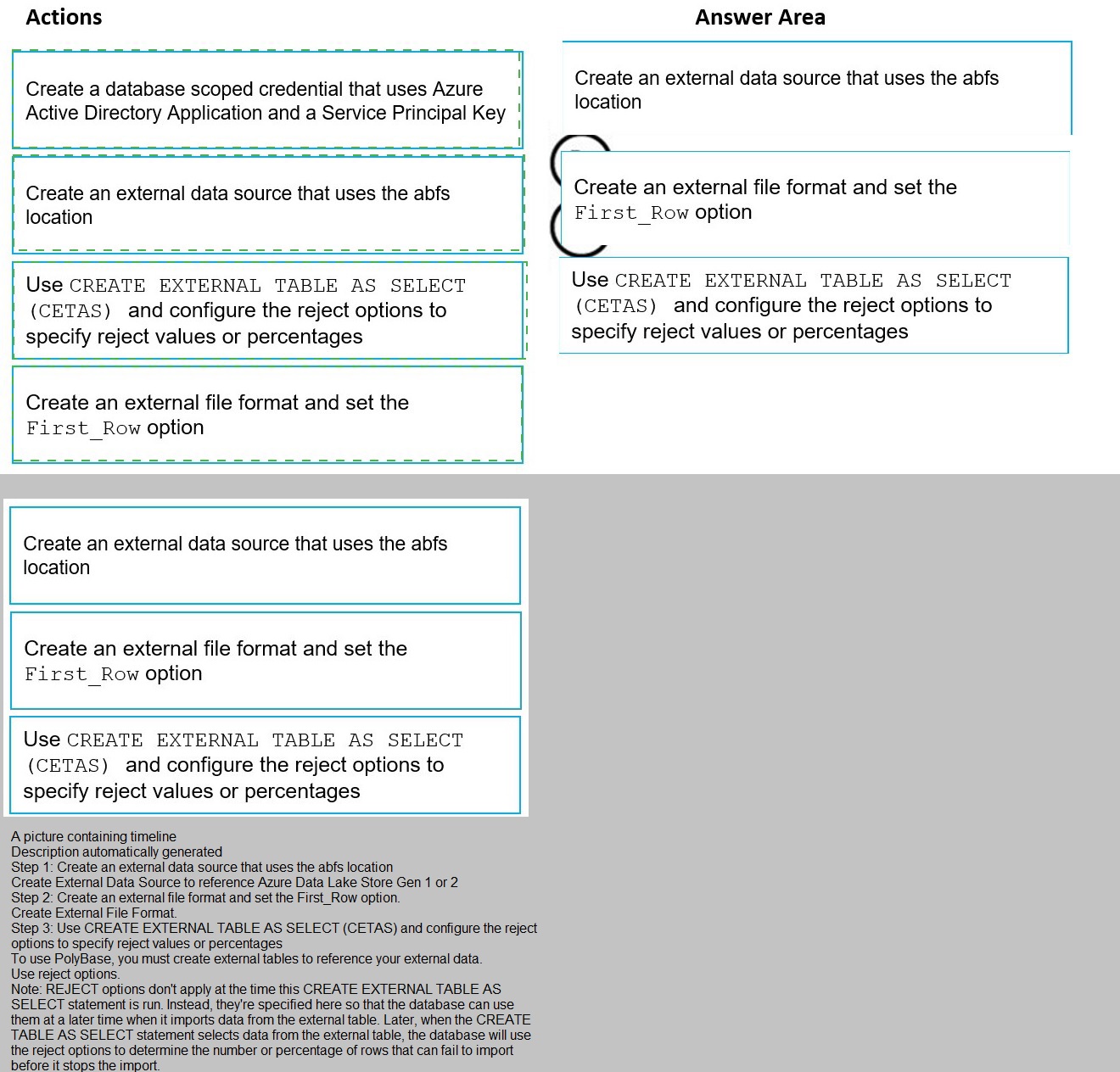
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each
file has a header row followed by a properly formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an enterprise data
warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before
building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
Which three actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: Each correct selection is worth one point
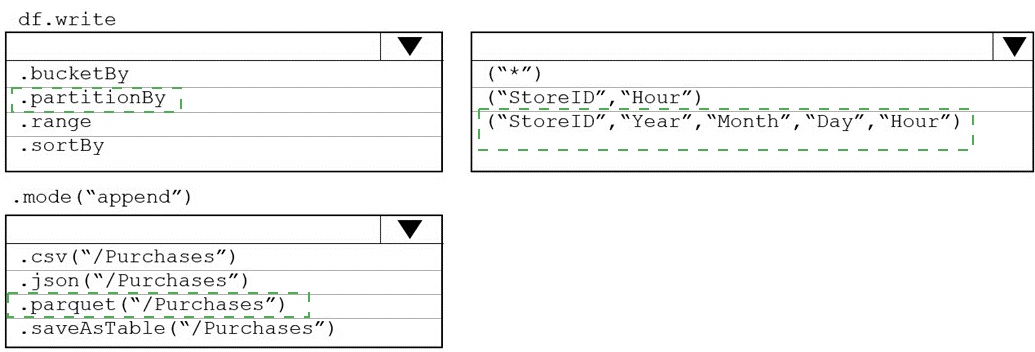
You plan to develop a dataset named Purchases by using Azure databricks Purchases will
contain the following columns:
• ProductID
• ItemPrice
• lineTotal
• Quantity
• StorelD
• Minute
• Month
• Hour
• Year
• Day
You need to store the data to support hourly incremental load pipelines that will vary for
each StoreID. the solution must minimize storage costs. How should you complete the
rode? To answer, select the appropriate options In the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Synapse Analytics dedicated SQL pool.
You run PDW_SHOWSPACEUSED(dbo,FactInternetSales’); and get the results shown in the following table.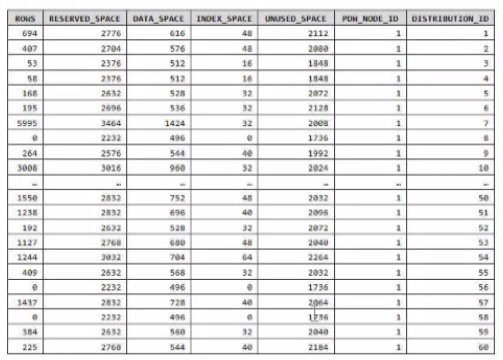
Which statement accurately describes the dbo,FactInternetSales table?
A.
The table contains less than 1,000 rows.
B.
All distribution contain data.
C.
The table is skewed.
D.
The table uses round-robin distribution.
The table is skewed.
Explanation:
Data skew means the data is not distributed evenly across the distributions.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-datawarehouse-
tables-distribute
| Page 7 out of 21 Pages |