Topic 3, Mix Questions
You are designing an Azure Data Lake Storage Gen2 container to store data for the human
resources (HR) department and the operations department at your company. You have the
following data access requirements:
• After initial processing, the HR department data will be retained for seven years.
• The operations department data will be accessed frequently for the first six months, and
then accessed once per month.
You need to design a data retention solution to meet the access requirements. The solution
must minimize storage costs.
Answer: See the answer in explanation.
Explanation:
Answer is below
You are processing streaming data from vehicles that pass through a toll booth.
You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window.
How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.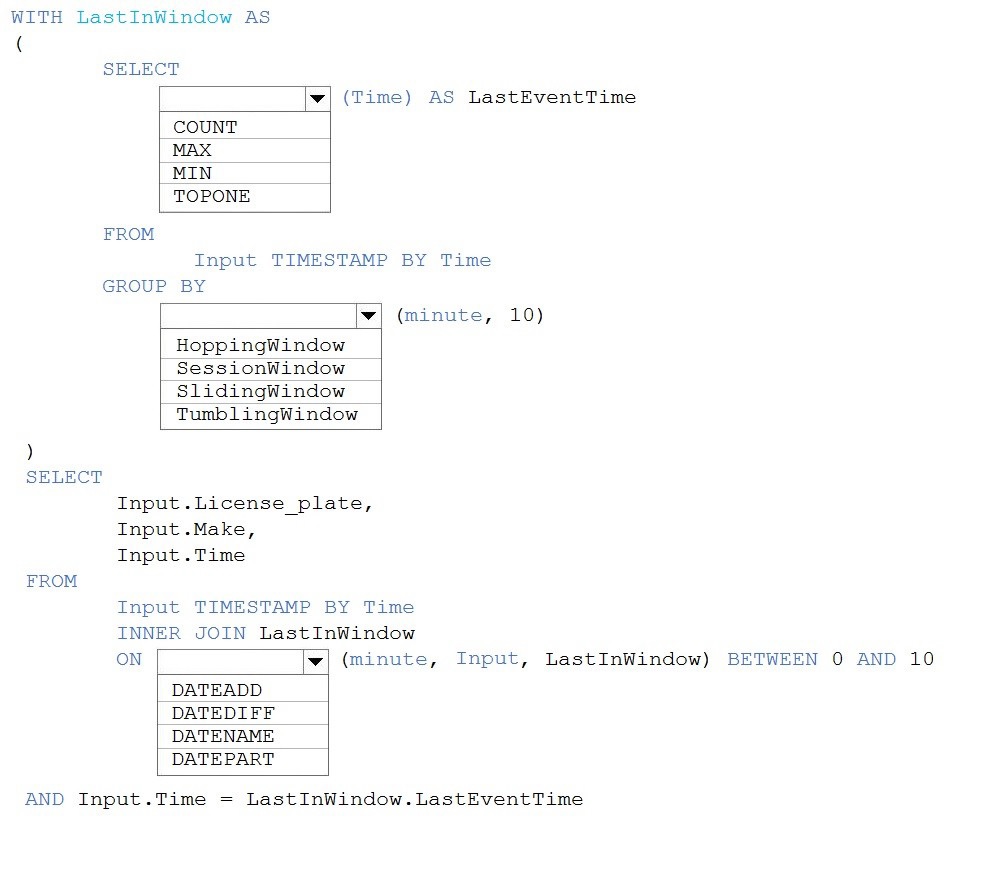
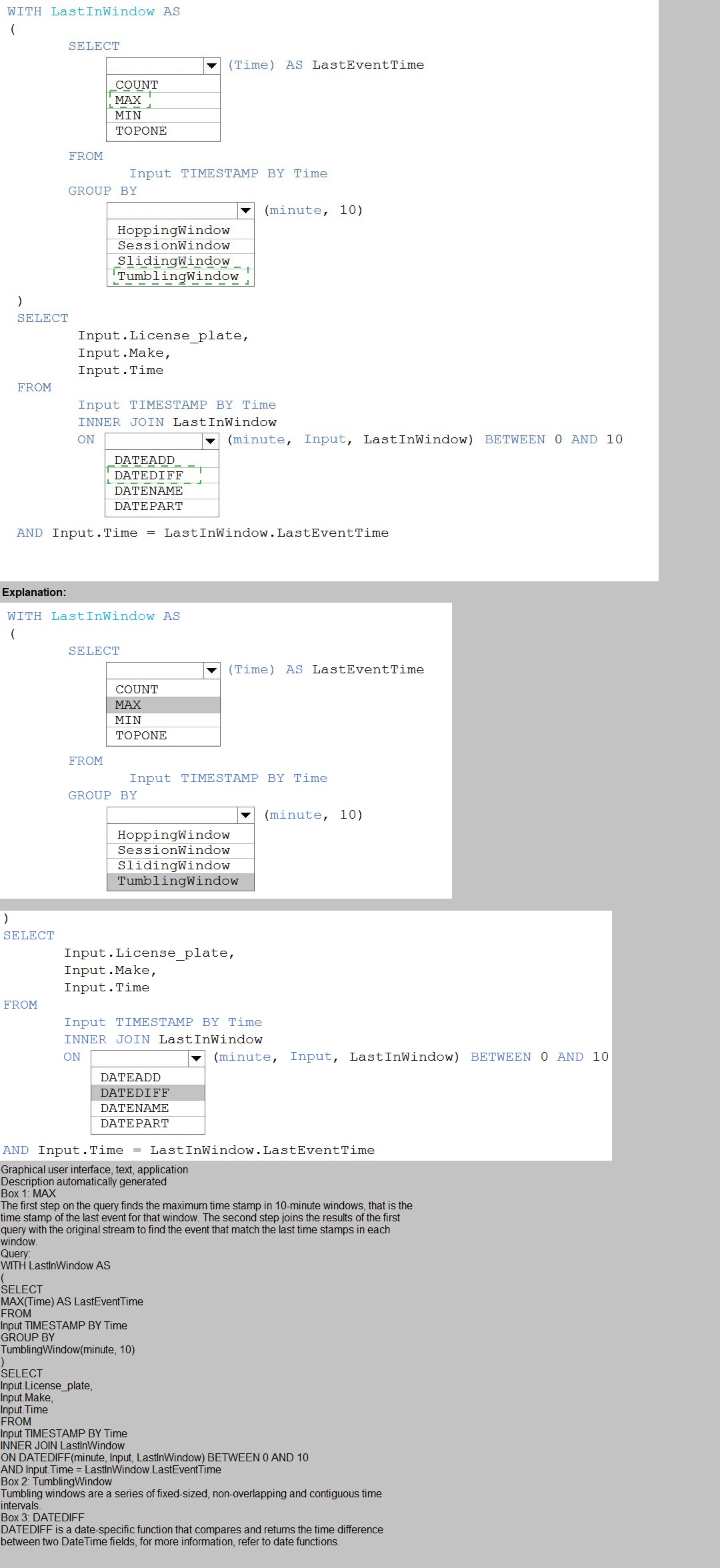
The following code segment is used to create an Azure Databricks cluster. 
You use Azure Data Lake Storage Gen2 to store data that data scientists and data
engineers will query by using Azure Databricks interactive notebooks. Users will have
access only to the Data Lake Storage folders that relate to the projects on which they work.
You need to recommend which authentication methods to use for Databricks and Data
Lake Storage to provide the users with the appropriate access. The solution must minimize
administrative effort and development effort.
Which authentication method should you recommend for each Azure service? To answer,
select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.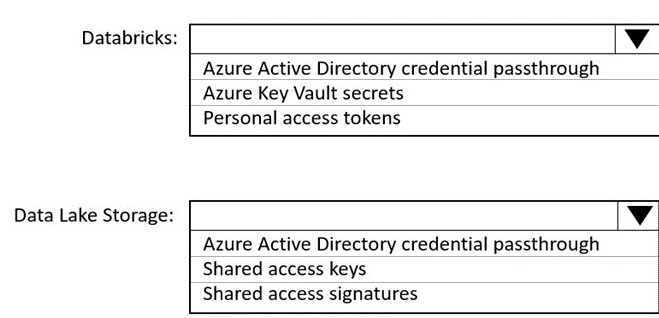

| Page 5 out of 21 Pages |