Topic 3, Mix Questions
You are building an Azure Stream Analytics job to identify how much time a user spends
interacting with a feature on a webpage.
The job receives events based on user actions on the webpage. Each row of data
represents an event. Each event has a type of either 'start' or 'end'.
You need to calculate the duration between start and end events.
How should you complete the query? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.

You have an Azure Storage account that generates 200.000 new files daily. The file names have a format of (YYY)/(MM)/(DD)/|HH])/(CustornerID).csv.
You need to design an Azure Data Factory solution that will toad new data from the storage account to an Azure Data lake once hourly. The solution must minimize load times and
costs.How should you configure the solution? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point
Answer: See the answer below in explanation.
Explanation:
The storage account container view is shown in the Refdata exhibit. (Click the Refdata tab.)
You need to configure the Stream Analytics job to pick up the new reference data. What
should you configure? To answer, select the appropriate options in the answer area NOTE:
Each correct selection is worth one point.
Answer: See the answer below in explanation.
Explanation:
Answer as below
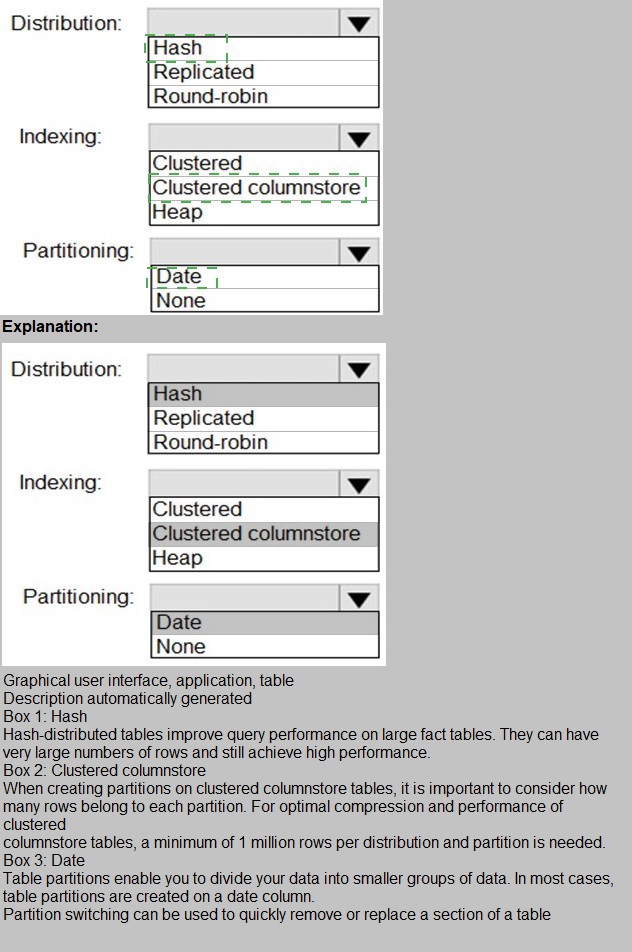
You have a SQL pool in Azure Synapse.
You plan to load data from Azure Blob storage to a staging table. Approximately 1 million
rows of data will be loaded daily. The table will be truncated before each daily load.
You need to create the staging table. The solution must minimize how long it takes to load
the data to the staging table.
How should you configure the table? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
You have two Azure Storage accounts named Storage1 and Storage2. Each account holds one container and has the hierarchical namespace enabled. The system has files that contain data stored in the Apache Parquet format.
You need to copy folders and files from Storage1 to Storage2 by using a Data Factory copy activity. The solution must meet the following requirements:
No transformations must be performed. The original folder structure must be retained. Minimize time required to perform the copy activity. How should you configure the copy activity? To answer, select the appropriate options in
the answer area.  NOTE: Each correct selection is worth one point.
NOTE: Each correct selection is worth one point.

| Page 4 out of 21 Pages |